Introduction
io_uring is one of the most ambitious kernel interfaces added in recent years: a shared-memory asynchronous I/O engine designed to avoid the syscall-heavy overhead of traditional read, write, and networking paths. That performance-oriented design also makes it unusually interesting from a security perspective, because the subsystem is full of long-lived shared state, lifetime-sensitive objects, and fast paths that interact closely with core kernel memory-management code.
This post first rebuilds the basic mental model for how io_uring works, then walks through two bugs that capture the kinds of exploitation surfaces the subsystem keeps exposing: a relative free in the classic provided-buffer path, and a mapped-page use-after-free in the newer buffer-ring registration path.
TL;DR
io_uringgets performance from shared state between user space and the kernel, and that same design makes lifetime bugs especially dangerous.- CVE-2021-41073 turns a buffer-selection confusion into a relative arbitrary free in
kmalloc-32. - CVE-2024-0582 turns mapped provided-buffer rings into a page-level use-after-free because the backing pages can be freed while still user-accessible.
- From an exploitation perspective, both bugs are valuable because they expose reusable primitives rather than narrow one-off crashes.
io_uring Background
io_uring is an API for asynchronous I/O operations. Rather than using the traditional syscall interface (read, write, and so on), it exposes a shared-memory model that lets user space submit work with minimal overhead and receive completions without bouncing through the classic syscall path for every operation. The interface relies on shared queues between user space and the kernel, which is what makes both its performance story and many of its bugs interesting.
Setup Model
At a high level, using io_uring looks like this:
- Set up the shared queues with
io_uring_setup:
#include <liburing.h>
int io_uring_setup(u32 entries, struct io_uring_params *params);
The io_uring_setup system call sets up a submission queue (SQ) and completion queue (CQ) with at least entries entries, and returns a file descriptor which can be used to perform subsequent operations on the io_uring instance. As stated before, the submission and completion queues are shared between user space and the kernel, which eliminates the need to copy data when initiating and completing I/O.
params is used by the application to pass options to the kernel, and by the kernel to convey information about the ring buffers:
struct io_uring_params {
__u32 sq_entries;
__u32 cq_entries;
__u32 flags;
__u32 sq_thread_cpu;
__u32 sq_thread_idle;
__u32 features;
__u32 wq_fd;
__u32 resv[3];
struct io_sqring_offsets sq_off;
struct io_cqring_offsets cq_off;
};
flags can take multiple (or zero) options OR’ed together, such as IORING_SETUP_IOPOLL and IORING_SETUP_HYBRID_IOPOLL.
If no flags are specified, the io_uring instance is setup for interrupt driven I/O.
The resv array must be initialized to zero. \
The rest of the fields are filled in by the kernel, and provide the information necessary to memory map(to get access from userspace) the submission queue, completion queue, and the array of submission queue entries.sq_entries specifies the number of submission queue entries allocated and sq_off describes the offsets of various ring buffer fields:
struct io_sqring_offsets {
__u32 head;
__u32 tail;
__u32 ring_mask;
__u32 ring_entries;
__u32 flags;
__u32 dropped;
__u32 array;
__u32 resv1;
__u64 user_addr;
};
So the submission queue can be mapped like this:
ptr = mmap(0, sq_off.array + sq_entries * sizeof(__u32),
PROT_READ|PROT_WRITE, MAP_SHARED|MAP_POPULATE,
ring_fd, IORING_OFF_SQ_RING);
where ring_fd is the fd returned from io_uring_setup.
The array of submission queue entries is mapped with:
sqentries = mmap(0, sq_entries * sizeof(struct io_uring_sqe),
PROT_READ|PROT_WRITE, MAP_SHARED|MAP_POPULATE,
ring_fd, IORING_OFF_SQES);
The completion queue is simpler, since the entries are not separated from the queue itself unlike the submission queue, and can be mapped with:
ptr = mmap(0, cq_off.cqes + cq_entries * sizeof(struct io_uring_cqe),
PROT_READ|PROT_WRITE, MAP_SHARED|MAP_POPULATE, ring_fd,
IORING_OFF_CQ_RING);
Submission Queue Entries
- For every I/O request you need to make (read a file, write a file, accept a socket connection, and so on), create a submission queue entry (SQE), describe the operation, and add it to the tail of the submission queue (SQ). One or more entries can be added.
Each I/O operation is, in essence, the equivalent of a system call you would have made otherwise, if you were not using io_uring.
For instance, a SQE with the opcode set to IORING_OP_READ is equivalent to thereadsystem call.
As you may have guessed, there are other opcodes: IORING_OP_WRITE, IORING_OP_SOCKET, IORING_OP_LISTEN ..etc
Concretely, we add an entry into the submission queue like this:
// Retrieving entries array
sring_array = sq_ptr + p.sq_off.array; // the mmaped address of SQ + sq_off.array: get the entries address
// retieving a new index from tail[....]
// Specifying the operation to do
struct io_uring_sqe *sqe = &sqes[index]; // using the index
sqe->opcode = IORING_OP_READ;
sqe->fd = 0; // read from stdin
sqe->addr = (unsigned long) buff; // into buff
// ....
// Call io_uring_enter(...) to perform the operation
Submitting Work
- Submit the queued work to the kernel with
io_uring_enter(...).
Note: in practice, liburing.h hides most of this setup and makes the interface much easier to use.
CVE-2021-41073
Credits: @chompie
Provided Buffers
In order to read/write into files, we can either supply buffers, or let the kernel choose pre-registered buffers with function io_provide_buffers:
static int io_provide_buffers(struct io_kiocb *req, unsigned int issue_flags)
{
struct io_provide_buf *p = &req->pbuf;
struct io_ring_ctx *ctx = req->ctx;
// [...]
list = head = xa_load(&ctx->io_buffers, p->bgid);
ret = io_add_buffers(p, &head);
// [...]
}
This function allocates kernel side objects struct io_buffer that contain the userspace provided buffer addresses from which to choose from.
Buffer Selection
For this second case, where kernel chooses an allocated buffer (struct io_buffer), at selection time:
static struct io_buffer *io_buffer_select(struct io_kiocb *req, size_t *len,
int bgid, struct io_buffer *kbuf,
bool needs_lock)
{
struct io_buffer *head;
// [...]
head = xa_load(&req->ctx->io_buffers, bgid);
if (head) {
if (!list_empty(&head->list)) {
kbuf = list_last_entry(&head->list, struct io_buffer,
list);
list_del(&kbuf->list);
// [...]
return kbuf;
}
function io_rw_buffer_select is called to select and return a working buffer kbuf->addr which is the provided userspace pointer:
static void __user *io_rw_buffer_select(struct io_kiocb *req, size_t *len,
bool needs_lock)
{
struct io_buffer *kbuf;
u16 bgid;
kbuf = (struct io_buffer *) (unsigned long) req->rw.addr;
bgid = req->buf_index;
kbuf = io_buffer_select(req, len, bgid, kbuf, needs_lock);
if (IS_ERR(kbuf))
return kbuf;
req->rw.addr = (u64) (unsigned long) kbuf; // [1]
req->flags |= REQ_F_BUFFER_SELECTED; // [2]
return u64_to_user_ptr(kbuf->addr);
}
After selecting a buffer at [1], the request is flagged with REQ_F_BUFFER_SELECTED as a way to track the buffer selection [2].
Where the Confusion Starts
But some confusion happened, because req->rw.addr is meant to be a userspace pointer, yet here, it is initialized with a kernel address of an struct io_buffer object in [1].
And more critically, for files that do not have ->read_iter() / ->write_iter() handlers like those in /proc , req->rw.addr is used as a user space pointer:
/*
* For files that don't have ->read_iter() and ->write_iter(), handle them
* by looping over ->read() or ->write() manually.
*/
static ssize_t loop_rw_iter(int rw, struct io_kiocb *req, struct iov_iter *iter)
{
struct kiocb *kiocb = &req->rw.kiocb;
struct file *file = req->file;
ssize_t ret = 0;
// [...]
while (iov_iter_count(iter)) {
struct iovec iovec;
ssize_t nr;
if (!iov_iter_is_bvec(iter)) {
iovec = iov_iter_iovec(iter);
} else {
iovec.iov_base = u64_to_user_ptr(req->rw.addr);
iovec.iov_len = req->rw.len;
}
if (rw == READ) {
nr = file->f_op->read(file, iovec.iov_base,
iovec.iov_len, io_kiocb_ppos(kiocb));
} else {
nr = file->f_op->write(file, iovec.iov_base,
iovec.iov_len, io_kiocb_ppos(kiocb));
}
if (nr < 0) {
if (!ret)
ret = nr;
break;
}
ret += nr;
if (nr != iovec.iov_len)
break;
req->rw.len -= nr;
req->rw.addr += nr; // [3]
iov_iter_advance(iter, nr);
}
return ret;
}
req->rw.addr is incremented after each iteration by the number of bytes nr that have been read/written [3]. This function is triggered with any of io_uring opcodes: IORING_OP_WRITEV ,IORING_OP_WRITE_FIXED or IORING_OP_WRITE.
Free Path
Upon request completion, io_put_rw_kbuf is called on the request object:
static inline unsigned int io_put_rw_kbuf(struct io_kiocb *req)
{
struct io_buffer *kbuf;
if (likely(!(req->flags & REQ_F_BUFFER_SELECTED))) // [4]
return 0;
kbuf = (struct io_buffer *) (unsigned long) req->rw.addr;
return io_put_kbuf(req, kbuf);
}
==>
static unsigned int io_put_kbuf(struct io_kiocb *req, struct io_buffer *kbuf)
{
unsigned int cflags;
cflags = kbuf->bid << IORING_CQE_BUFFER_SHIFT;
cflags |= IORING_CQE_F_BUFFER;
req->flags &= ~REQ_F_BUFFER_SELECTED; // Removing REQ_F_BUFFER_SELECTED flag
kfree(kbuf); // [5]
return cflags;
}
These two functions check that req->rw.addr is a selected buffer(REQ_F_BUFFER_SELECTED) and then free it with kfree(kbuf) in [5], which is actually kfree(kbuf+number of processed bytes) in function loop_rw_iter.
Exploitation Primitive
And since struct io_buffer is 32-byte structure and is allocated without cache isolation:
static int io_add_buffers(struct io_provide_buf *pbuf, struct io_buffer **head)
{
struct io_buffer *buf;
u64 addr = pbuf->addr;
int i, bid = pbuf->bid;
for (i = 0; i < pbuf->nbufs; i++) {
buf = kmalloc(sizeof(*buf), GFP_KERNEL); // No cache isolation
// [...]
}
}
So, we get a relative arbitrary free primitive in the kmalloc-32 cache slab.
Exploitation
The goal like for most exploitation cases is to get a leaking primitive to get slab addresses and function pointer addresses to bypass KASLR, and an object overwriting primitive to redirect control flow.
This arbitrary free can turned into a leaking and overwriting primitives, simply by freeing kmalloc-32 cache objects that are can be read like struct shm_file_data and seq_operations, struct io_buffer, adding to that the setxattr(+FUSE/userfaultfd) than can allocate any size and the user can read/write any data in it.
CVE-2024-0582
Note: The following is code is from v6.5.3, which differs from the previous one interms of io_uring features.
As new feature since v6.4, the kernel can handle the registering of io_buffers without the user providing userspace buffers.
Registering io buffers
Register Path
Registering provided buffers in the register syscall with IORING_REGISTER_PBUF_RING:
static int __io_uring_register(struct io_ring_ctx *ctx, unsigned opcode,
void __user *arg, unsigned nr_args)
__releases(ctx->uring_lock)
__acquires(ctx->uring_lock)
{
int ret;
// [...]
case IORING_REGISTER_PBUF_RING:
ret = -EINVAL;
if (!arg || nr_args != 1)
break;
ret = io_register_pbuf_ring(ctx, arg);
break;
// [...]
}
And io_register_pbuf_ring looks like:
int io_register_pbuf_ring(struct io_ring_ctx *ctx, void __user *arg)
{
struct io_uring_buf_reg reg;
struct io_buffer_list *bl, *free_bl = NULL;
int ret;
if (copy_from_user(®, arg, sizeof(reg))) // Copying the args from userspace
return -EFAULT;
// [...]
bl = io_buffer_get_list(ctx, reg.bgid);
if (bl) {
/* if mapped buffer ring OR classic exists, don't allow */
if (bl->is_mapped || !list_empty(&bl->buf_list))
return -EEXIST;
} else {
free_bl = bl = kzalloc(sizeof(*bl), GFP_KERNEL); // No cache isolation for the io_buffers list
if (!bl)
return -ENOMEM;
}
if (!(reg.flags & IOU_PBUF_RING_MMAP))
ret = io_pin_pbuf_ring(®, bl);
else
ret = io_alloc_pbuf_ring(®, bl); // [6]
if (!ret) {
bl->nr_entries = reg.ring_entries;
bl->mask = reg.ring_entries - 1;
io_buffer_add_list(ctx, bl, reg.bgid); // [7]
return 0;
}
// [...]
}
Page-backed Buffer Rings
In case arg is flagged with IOU_PBUF_RING_MMAP, it calls:
static int io_alloc_pbuf_ring(struct io_uring_buf_reg *reg,
struct io_buffer_list *bl)
{
gfp_t gfp = GFP_KERNEL_ACCOUNT | __GFP_ZERO | __GFP_NOWARN | __GFP_COMP;
size_t ring_size;
void *ptr;
ring_size = reg->ring_entries * sizeof(struct io_uring_buf_ring);
ptr = (void *) __get_free_pages(gfp, get_order(ring_size)); // [8]
if (!ptr)
return -ENOMEM;
bl->buf_ring = ptr;
bl->is_mapped = 1;
bl->is_mmap = 1;
return 0;
}
This function allocates the necessary memory for the entries using the page allocator __get_free_pages [8], and stores the returned pages address in bl->buf_ring.
It sets flags is_mapped and is_mmap which 1, which means that these newly allocated buffers are mmaped to userspace.
In [7], bl is then added to to the io_buffers list, which makes it ready for use by mapping it from the userspace:
static const struct file_operations io_uring_fops = {
.release = io_uring_release,
.mmap = io_uring_mmap,
// [...]
Unregistering io buffers
Unregister Path
Same as registering, unregistering is handled in __io_uring_register(:
static int __io_uring_register(struct io_ring_ctx *ctx, unsigned opcode,
void __user *arg, unsigned nr_args)
__releases(ctx->uring_lock)
__acquires(ctx->uring_lock)
{
int ret;
// [...]
case IORING_UNREGISTER_PBUF_RING:
ret = -EINVAL;
if (!arg || nr_args != 1)
break;
ret = io_unregister_pbuf_ring(ctx, arg); // [9]
break;
// [...]
}
In [9], io_unregister_pbuf_ring simply grabs the io_uring_buf_reg arg, and frees its corresponding buffer list bl:
int io_unregister_pbuf_ring(struct io_ring_ctx *ctx, void __user *arg)
{
struct io_uring_buf_reg reg;
struct io_buffer_list *bl;
if (copy_from_user(®, arg, sizeof(reg)))
return -EFAULT;
if (reg.resv[0] || reg.resv[1] || reg.resv[2])
return -EINVAL;
if (reg.flags)
return -EINVAL;
bl = io_buffer_get_list(ctx, reg.bgid);
if (!bl)
return -ENOENT;
if (!bl->is_mapped)
return -EINVAL;
__io_remove_buffers(ctx, bl, -1U);
if (bl->bgid >= BGID_ARRAY) {
xa_erase(&ctx->io_bl_xa, bl->bgid);
kfree(bl);
}
return 0;
}
Freeing the Mapped Pages
bl->buf_ring is freed with io_remove_buffers -> free_compound_page in [10]:
static int __io_remove_buffers(struct io_ring_ctx *ctx,
struct io_buffer_list *bl, unsigned nbufs)
{
unsigned i = 0;
/* shouldn't happen */
if (!nbufs)
return 0;
if (bl->is_mapped) {
i = bl->buf_ring->tail - bl->head;
if (bl->is_mmap) {
struct page *page;
page = virt_to_head_page(bl->buf_ring);
if (put_page_testzero(page))
free_compound_page(page); // [10]
bl->buf_ring = NULL;
bl->is_mmap = 0;
// [...]
}
bl->is_mmap and bl->is_mapped are reset to 0.
Resulting Primitive
These buffers can be mapped into userspace with flag VM_PFNMAP which means that pages refcount isn’t incremented during mmap.
Then after calling free_compound_page, the kernel frees these pages even if they’re still mapped in userspace since the refcount isn’t incremented, and they are returns into the page allocator. \ Hence, user can still access them: UAF.
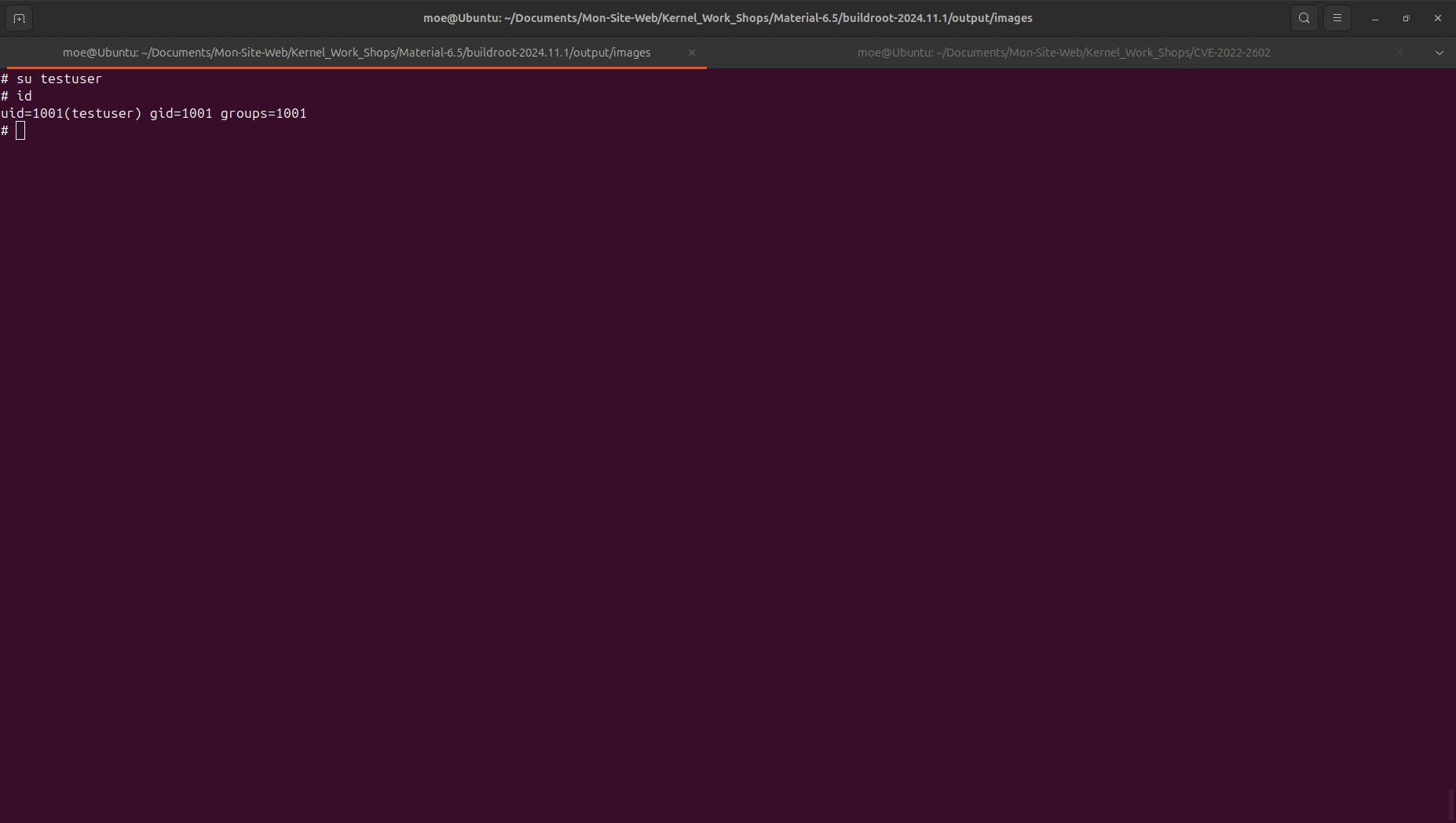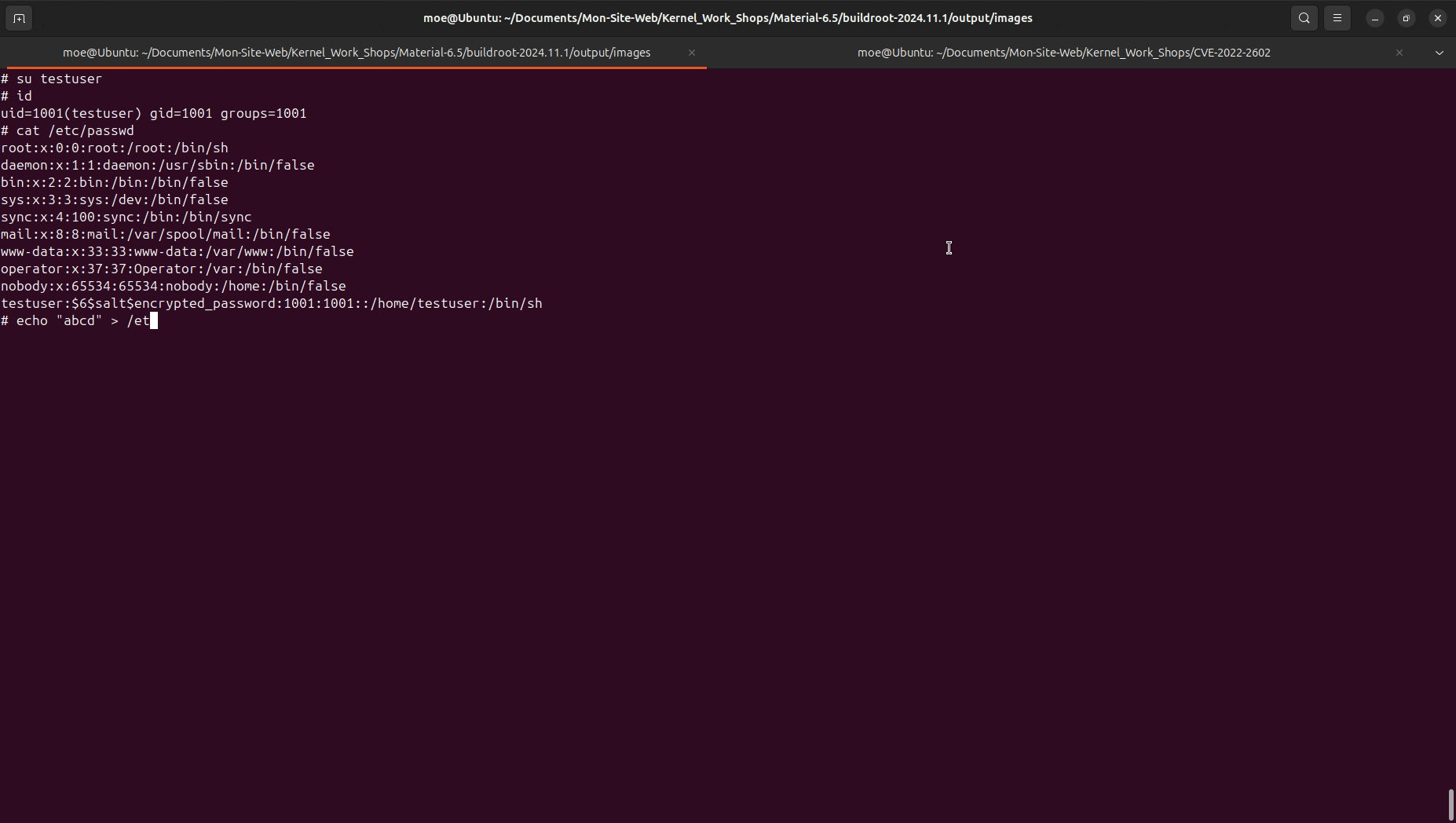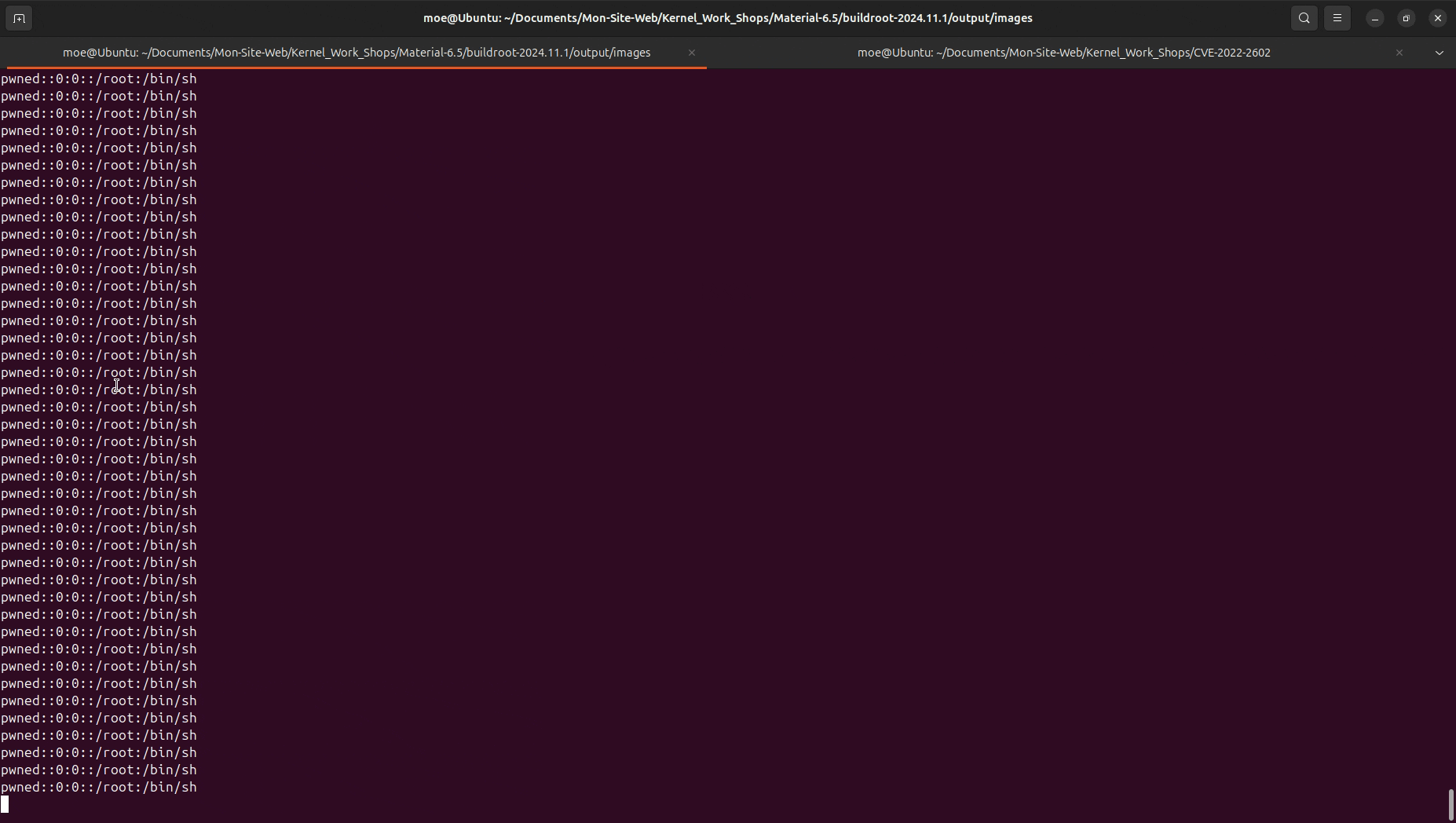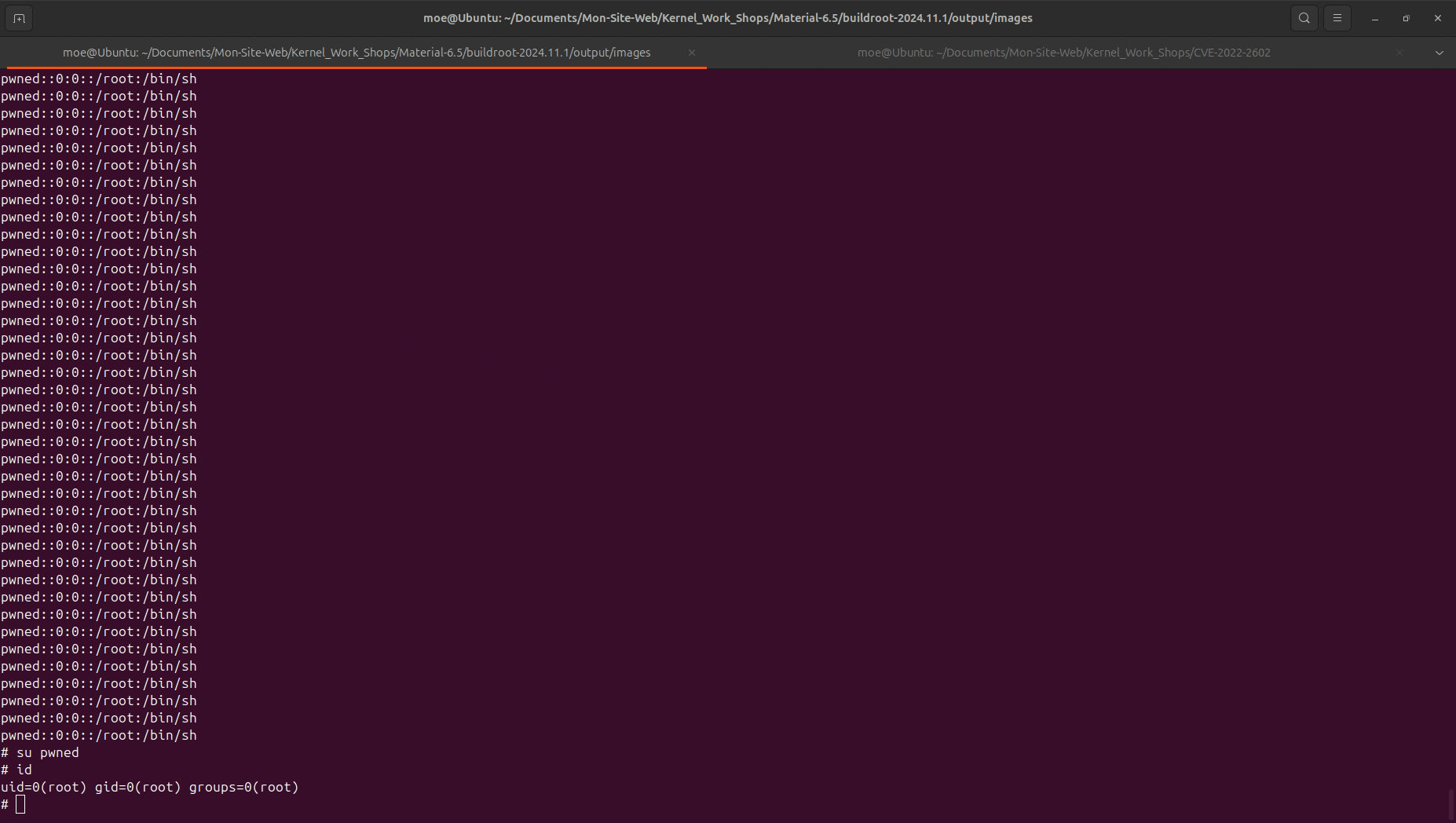
This is a very powerful exploitation primitive sinice we can do read/write operations on kernel pages which then could be forced into getting reallocated with interesing objects.
Exploitation
There are many exploit strategies that come to mind: f_mode modification, DirtyPTE, PageJacking …etc or even non data-only like simply ROPing by corruption pipe objects for example.
Conclusion
The recurring theme in these bugs is that io_uring is not merely “an async I/O API”; it is a large shared-state subsystem whose fast paths continuously translate between user pointers, kernel objects, pinned memory, and mapped pages. That creates exactly the sort of lifetime and ownership confusion that exploit development thrives on.
Viewed together, CVE-2021-41073 and CVE-2024-0582 show two different but equally useful outcomes: one yields a slab-level free primitive, the other a page-backed UAF primitive. The details differ, but the lesson is the same: whenever io_uring introduces a new mechanism for sharing memory or tracking buffers across user/kernel boundaries, it deserves close scrutiny.