Introduction
io_uring has been a heavily targeted subsystem in the Linux kernel — at one point it constituted 60% of kCTF entries (source). As with most newly introduced features, io_uring — since its introduction in 2019 — has been very bug-prone.
CVE-2024-0582 is a page use-after-free discovered by Jann Horn and later discussed in an Exodus Intel blog post. This post walks through the io_uring basics needed to understand the bug, then explores exploitation paths — from file-structure spraying to sk_buff-based RIP hijacking.
io_uring — Basic Concepts
The core idea: rather than using traditional syscalls (read, write, …), io_uring allows zero-copy operations with minimal overhead to communicate with the kernel. It uses shared buffers between user-space and kernel as a means for communication and data transfer.
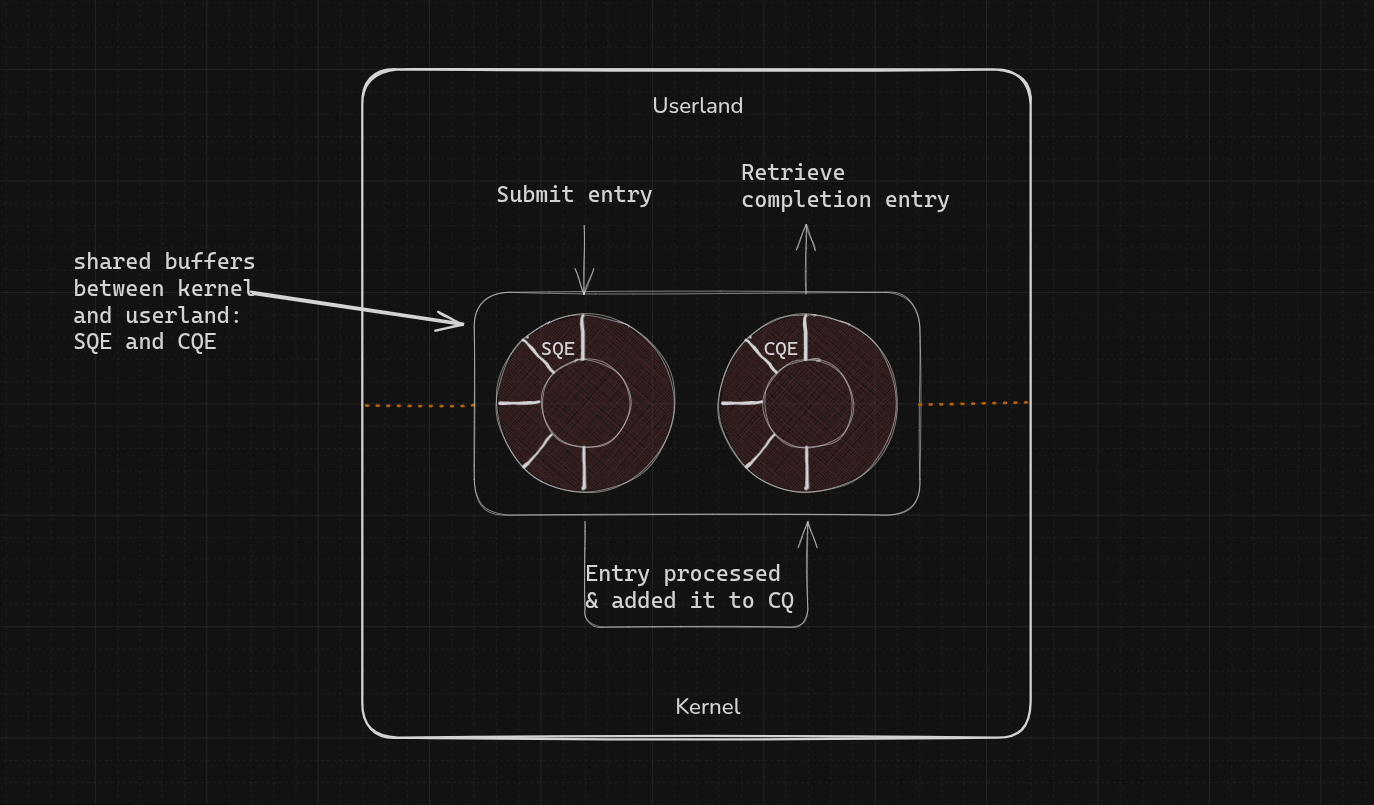
Briefly, here is how it works:
Phase I — Setup
int io_uring_setup(u32 entries, struct io_uring_params *params);
io_uring_setup creates a submission queue (SQ) and completion queue (CQ) with at least entries entries, and returns a file descriptor for subsequent operations on the io_uring instance. The submission and completion queues are shared between user-space and the kernel, which eliminates the need to copy data when initiating and completing I/O. These buffers are mapped and managed using data retrieved from the second argument struct io_uring_params *params after calling setup:
struct io_uring_params {
__u32 sq_entries;
__u32 cq_entries;
__u32 flags;
__u32 sq_thread_cpu;
__u32 sq_thread_idle;
__u32 features;
__u32 wq_fd;
__u32 resv[3];
struct io_sqring_offsets sq_off;
struct io_cqring_offsets cq_off;
};
Phase II — Submitting Request Entries
For every I/O request (read a file, write a file, accept a socket connection, …), we create a submission queue entry (SQE) describing the operation, then add it to the tail of the SQ. One or more entries can be added at a time.
Each I/O operation is, in essence, the equivalent of a system call. For instance, an SQE with the opcode set to IORING_OP_READ is equivalent to the read system call. Other opcodes include IORING_OP_WRITE, IORING_OP_SOCKET, IORING_OP_LISTEN, and so on.
// Specifying the operation to do
struct io_uring_sqe *sqe = &sqes[index]; // using the index
sqe->opcode = IORING_OP_READ;
sqe->fd = 0; // read from stdin for example
sqe->addr = (unsigned long) buff; // into buff [1]
At [1], a user-space buffer is supplied so that the kernel reads into it. More on this right after.
Phase III — Retrieving Results
The kernel processes the request entry, and when it finishes, a io_uring_cqe (Completion Queue Event) is placed into the CQ, which can then be retrieved from user-space.
In order to do buffered operations, we can either supply buffers, or let the kernel choose pre-registered user-space buffers with io_provide_buffers. Since v6.4, the kernel can handle their registration without user-supplied buffers — they instead get allocated in the kernel and then mapped into user-space for usage.
Registering IO Buffers
Registering provided buffers in the register syscall with IORING_REGISTER_PBUF_RING:
static int __io_uring_register(struct io_ring_ctx *ctx, unsigned opcode,
void __user *arg, unsigned nr_args)
__releases(ctx->uring_lock)
__acquires(ctx->uring_lock)
{
int ret;
// [...]
case IORING_REGISTER_PBUF_RING:
ret = -EINVAL;
if (!arg || nr_args != 1)
break;
ret = io_register_pbuf_ring(ctx, arg);
break;
// [...]
}
And io_register_pbuf_ring looks like:
int io_register_pbuf_ring(struct io_ring_ctx *ctx, void __user *arg)
{
struct io_uring_buf_reg reg;
struct io_buffer_list *bl, *free_bl = NULL;
int ret;
if (copy_from_user(®, arg, sizeof(reg))) // Copying the args from userspace
return -EFAULT;
// [...]
bl = io_buffer_get_list(ctx, reg.bgid);
if (bl) {
/* if mapped buffer ring OR classic exists, don't allow */
if (bl->is_mapped || !list_empty(&bl->buf_list))
return -EEXIST;
} else {
free_bl = bl = kzalloc(sizeof(*bl), GFP_KERNEL); // No cache isolation for the io_buffers list
if (!bl)
return -ENOMEM;
}
if (!(reg.flags & IOU_PBUF_RING_MMAP))
ret = io_pin_pbuf_ring(®, bl);
else
ret = io_alloc_pbuf_ring(®, bl); // [2]
if (!ret) {
bl->nr_entries = reg.ring_entries;
bl->mask = reg.ring_entries - 1;
io_buffer_add_list(ctx, bl, reg.bgid); // [3]
return 0;
}
// [...]
}
In case reg is flagged with IOU_PBUF_RING_MMAP, at [2] it calls:
static int io_alloc_pbuf_ring(struct io_uring_buf_reg *reg,
struct io_buffer_list *bl)
{
gfp_t gfp = GFP_KERNEL_ACCOUNT | __GFP_ZERO | __GFP_NOWARN | __GFP_COMP;
size_t ring_size;
void *ptr;
ring_size = reg->ring_entries * sizeof(struct io_uring_buf_ring);
ptr = (void *) __get_free_pages(gfp, get_order(ring_size)); // [4]
if (!ptr)
return -ENOMEM;
bl->buf_ring = ptr;
bl->is_mapped = 1;
bl->is_mmap = 1;
return 0;
}
This function allocates the necessary memory for the entries using the page allocator __get_free_pages [4], and stores the returned pages address in bl->buf_ring. It sets flags is_mapped and is_mmap to 1, meaning these newly allocated buffers are mmap’d to user-space.
At [3], bl is then added to a grouped io_buffers list identified by bgid, making it ready for use by mapping it from user-space:
static const struct file_operations io_uring_fops = {
.release = io_uring_release,
.mmap = io_uring_mmap, // <-----
// [...]
From user-space, we trigger these operations like so:
struct io_uring_buf_reg reg;
memset(®, 0, sizeof(reg));
reg.ring_entries = 256; // number of `io_uring_buf_ring` objects to allocate
reg.bgid = 1; // bgid
reg.flags = IOU_PBUF_RING_MMAP;
if (io_uring_register(ring_fd, IORING_REGISTER_PBUF_RING, ®, 1) < 0) {
perror("io_uring_register");
close(ring_fd);
return 1;
}
When using this feature, the kernel picks one of the allocated buffers from the specified bgid using the flag REQ_F_BUFFER_SELECT:
static struct iovec *__io_import_iovec(int ddir, struct io_kiocb *req,
struct io_rw_state *s,
unsigned int issue_flags)
{
struct io_rw *rw = io_kiocb_to_cmd(req, struct io_rw);
struct iov_iter *iter = &s->iter;
u8 opcode = req->opcode;
struct iovec *iovec;
void __user *buf;
size_t sqe_len;
ssize_t ret;
// [...]
if (opcode == IORING_OP_READ || opcode == IORING_OP_WRITE ||
(req->flags & REQ_F_BUFFER_SELECT)) {
if (io_do_buffer_select(req)) {
buf = io_buffer_select(req, &sqe_len, issue_flags);
if (!buf)
return ERR_PTR(-ENOBUFS);
rw->addr = (unsigned long) buf;
rw->len = sqe_len;
}
rw->addr and rw->len are then used to perform read/write operations.
Unregistering IO Buffers
Unregistering is handled in __io_uring_register with the IORING_UNREGISTER_PBUF_RING flag, which calls io_unregister_pbuf_ring:
int io_unregister_pbuf_ring(struct io_ring_ctx *ctx, void __user *arg)
{
struct io_uring_buf_reg reg;
struct io_buffer_list *bl;
// [...]
bl = io_buffer_get_list(ctx, reg.bgid);
if (!bl)
return -ENOENT;
if (!bl->is_mapped)
return -EINVAL;
__io_remove_buffers(ctx, bl, -1U);
// [...]
}
Which down the line retrieves the bgid’s corresponding buffer and frees it:
static int __io_remove_buffers(struct io_ring_ctx *ctx,
struct io_buffer_list *bl, unsigned nbufs)
{
unsigned i = 0;
/* shouldn't happen */
if (!nbufs)
return 0;
if (bl->is_mapped) {
i = bl->buf_ring->tail - bl->head;
if (bl->is_mmap) {
struct page *page;
page = virt_to_head_page(bl->buf_ring);
if (put_page_testzero(page))
free_compound_page(page); // [5]
bl->buf_ring = NULL;
bl->is_mmap = 0;
// [...]
}
The Vulnerability
As explained in detail by Oriol Castejón, during the mmap operation these buffers are mapped into user-space with the VM_PFNMAP flag:
mmap = io_uring_mmap
-> remap_pfn_range
-> remap_pfn_range_notrack
int remap_pfn_range_notrack(struct vm_area_struct *vma, unsigned long addr,
unsigned long pfn, unsigned long size, pgprot_t prot)
{
pgd_t *pgd;
unsigned long next;
unsigned long end = addr + PAGE_ALIGN(size);
struct mm_struct *mm = vma->vm_mm;
int err;
if (WARN_ON_ONCE(!PAGE_ALIGNED(addr)))
return -EINVAL;
/*
* Physically remapped pages are special. Tell the
* rest of the world about it:
* VM_IO tells people not to look at these pages
* (accesses can have side effects).
* VM_PFNMAP tells the core MM that the base pages are just
* raw PFN mappings, and do not have a "struct page" associated
* with them.
* VM_DONTEXPAND
* Disable vma merging and expanding with mremap().
* VM_DONTDUMP
* Omit vma from core dump, even when VM_IO turned off.
*
* There's a horrible special case to handle copy-on-write
* behaviour that some programs depend on. We mark the "original"
* un-COW'ed pages by matching them up with "vma->vm_pgoff".
* See vm_normal_page() for details.
*/
if (is_cow_mapping(vma->vm_flags)) {
if (addr != vma->vm_start || end != vma->vm_end)
return -EINVAL;
vma->vm_pgoff = pfn;
}
vm_flags_set(vma, VM_IO | VM_PFNMAP | VM_DONTEXPAND | VM_DONTDUMP);
// [...]
}
As the developers’ comment notes, VM_PFNMAP means the pages are raw PFN mappings with no backing struct page — there is no refcounting or mapcounting. Therefore, after calling free_compound_page at [5], the kernel frees these pages even though they are still mapped in user-space. The pages are returned to the page allocator while user-space retains access: a page use-after-free.
This is a very powerful exploitation primitive — we can perform read/write operations on kernel pages that can be forced into reallocation with interesting objects.
Exploitation
Many paths are available since the primitive is powerful. For the sake of experimentation, several strategies were tested:
- File structure spraying using
/etc/passwdandf_modeattribute corruption. - Socket buffers (
sk_buff) to hijack execution flow and obtain an arbitrary write.
Strategy (1) has been well documented elsewhere:
- Exodus Intel — Mind the Patch Gap
- kuzeyardabulut — CVE-2024-0582 dirty_cred
- nasm.re — cryptodev-linux vuln
So no need to reiterate. But before moving into the core exploitation, let’s quickly see how page claiming and reclaiming works.
Page Allocator Internals
RAM is organized into NUMA nodes; to inspect your machine:
numactl --hardware # or
ls -d /sys/devices/system/node/node*
For a regular personal machine (x86, 16 GB), the RAM layout looks like:
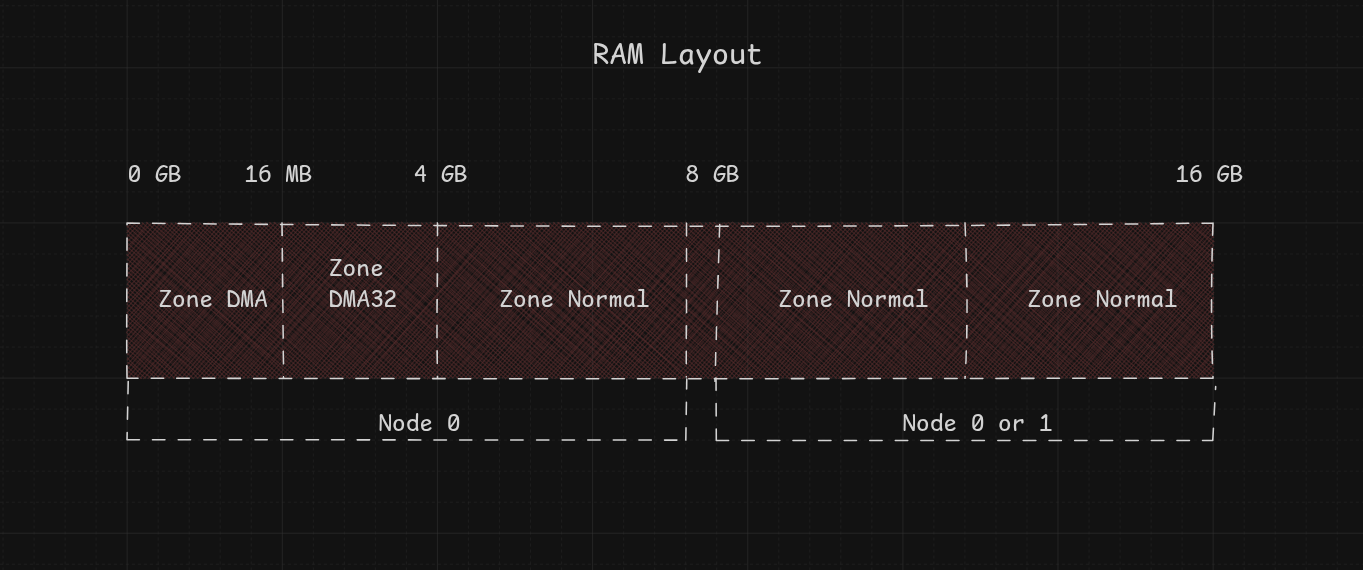
From the official kernel documentation:
ZONE_DMAandZONE_DMA32historically represented memory suitable for DMA by peripheral devices that cannot access all addressable memory. For many years there have been better, more robust interfaces for DMA-specific requirements (Dynamic DMA mapping using the generic device), butZONE_DMAandZONE_DMA32still represent memory ranges with access restrictions. Depending on the architecture, either or both zone types can be disabled at build time viaCONFIG_ZONE_DMAandCONFIG_ZONE_DMA32.ZONE_NORMALis for normal memory accessible by the kernel at all times. DMA operations can be performed on pages in this zone if the DMA device supports transfers to all addressable memory.ZONE_NORMALis always enabled.
A node object is represented by:
typedef struct pglist_data {
/*
* node_zones contains just the zones for THIS node. Not all of the
* zones may be populated, but it is the full list. It is referenced by
* this node's node_zonelists as well as other node's node_zonelists.
*/
struct zone node_zones[MAX_NR_ZONES];
int nr_zones; /* number of populated zones in this node */
// [...]
} pg_data_t;
A zone is represented by:
struct zone {
// [...]
struct per_cpu_pages __percpu *per_cpu_pageset;
// [...]
struct free_are free_area[NR_PAGE_ORDERS];
// [...]
} ____cacheline_internodealigned_in_smp;
per_cpu_pageset is the fast path for pages of order <= 3; otherwise free_area is used. per_cpu_pageset is tagged __percpu, meaning each CPU keeps its own page set.
This has an important implication for exploitation: if we give, say, 4 CPUs to our QEMU VM, io_uring might allocate and free pages on CPU 1 while our spraying happens on CPU 3 — which would fail the attempt. We need to force page handling onto a single CPU for both the io_uring worker and the spraying process. This is achieved by pinning the CPU from the user-space process and pinning the io worker CPU using liburing’s dedicated function.
For more detail on the page allocator, a recommended read is syst3mfailure.io — Linux Page Allocator.
Choosing Spray Objects
In kernel exploitation, choosing the right objects to spray is critical. Several candidates were considered:
msg_queue objects:
int ms_qid[0x100];
for (int i = 0; i < 0x100; i++)
{
ms_qid[i] = msgget(IPC_PRIVATE, 0666 | IPC_CREAT);
if (ms_qid[i] < 0)
{
puts("[x] msgget!");
return -1;
}
}
Calling msgsnd to send a message of a specified size on the specified message queue creates a msg_msg object. Calling msgsnd many times lets us spray msg_msg objects.
seq_file objects:
long seq_fd[0x200];
for (int i = 0; i < 0x200; i++)
seq_fd[i] = open("/proc/self/stat", O_RDONLY);
All of these are interesting objects, but I ended up choosing socket buffer sk_buff objects, since with these we have access to user-controlled data: skb->data. The idea is to spray skb objects and use FUSE-mapped buffers to delay data copying, then race to modify skb->data to point to the cred structure or modprobe_path just before writing.
Phase I — Spraying File Structures
This step involves spraying file objects to obtain interesting kernel addresses — specifically struct file_operations and struct cred.
struct file_operations for regular files is initialized to ext4_file_operations, a global variable at a known offset. From this, we can deduce the kernel base address and defeat KASLR. By corrupting the pointer and making it point to an address with controlled data, we can hijack RIP.
In this phase, we spray many objects by simply opening any readable file:
int files[1000];
for(int i = 0 ; i < 100 ; i++) {
files[i] = open("/etc/passwd", O_RDONLY);
}
Phase II — Socket Buffer sk_buff Spraying
First, we allocate sockets with socketpair(AF_UNIX, SOCK_STREAM, 0, sk_socket[i]), then at writing time we call write(sk_socket[i][0], buf, size) — this is where skb is allocated:
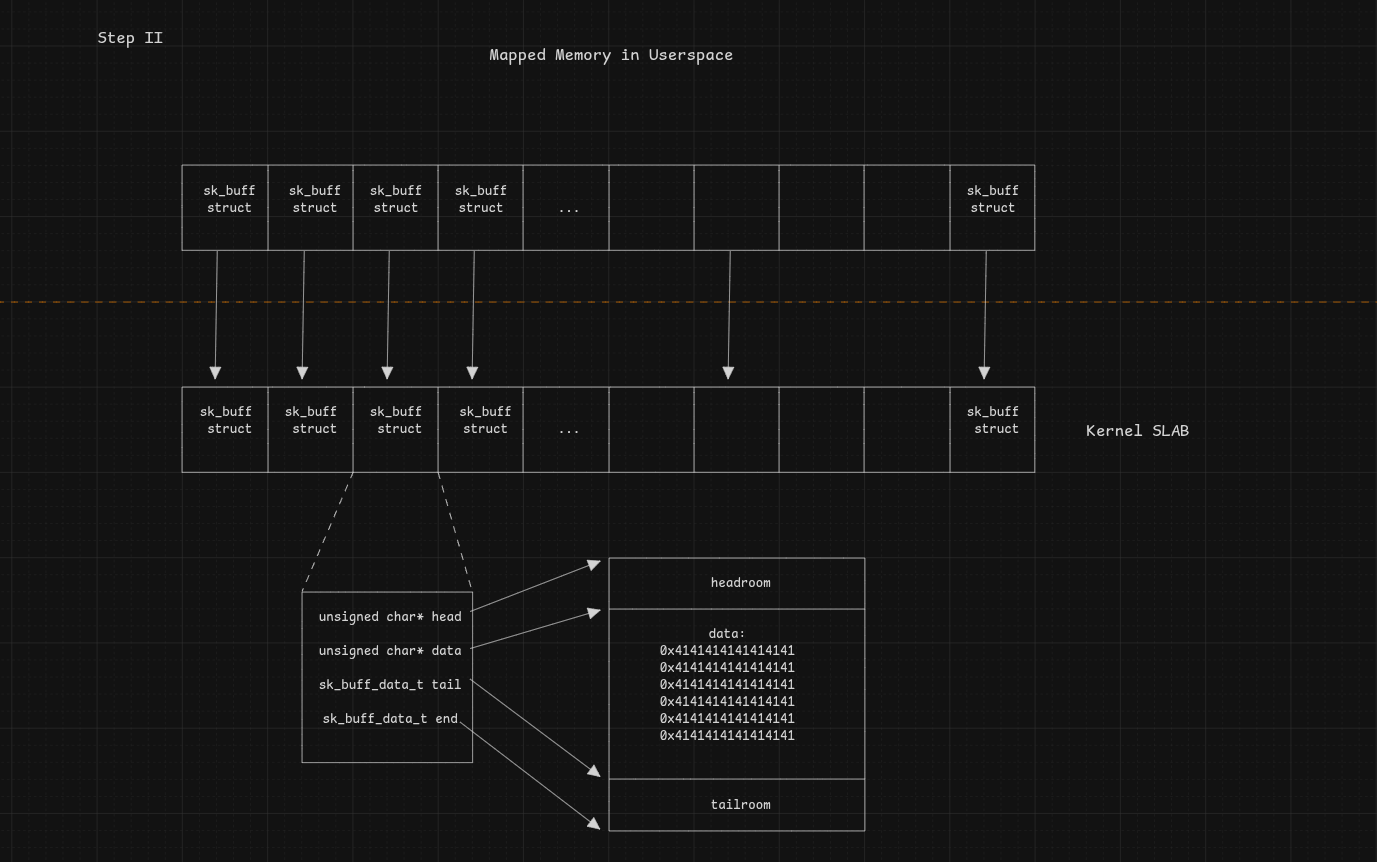
In this picture, we can see that 0x4141414141414141 integers are stored in skb->data, but this could be anything since it is user-controlled. After obtaining the kernel base, we store function addresses instead in order to redirect execution.
After spraying, we free the sk_buff objects by receiving the messages, reaching this memory state:
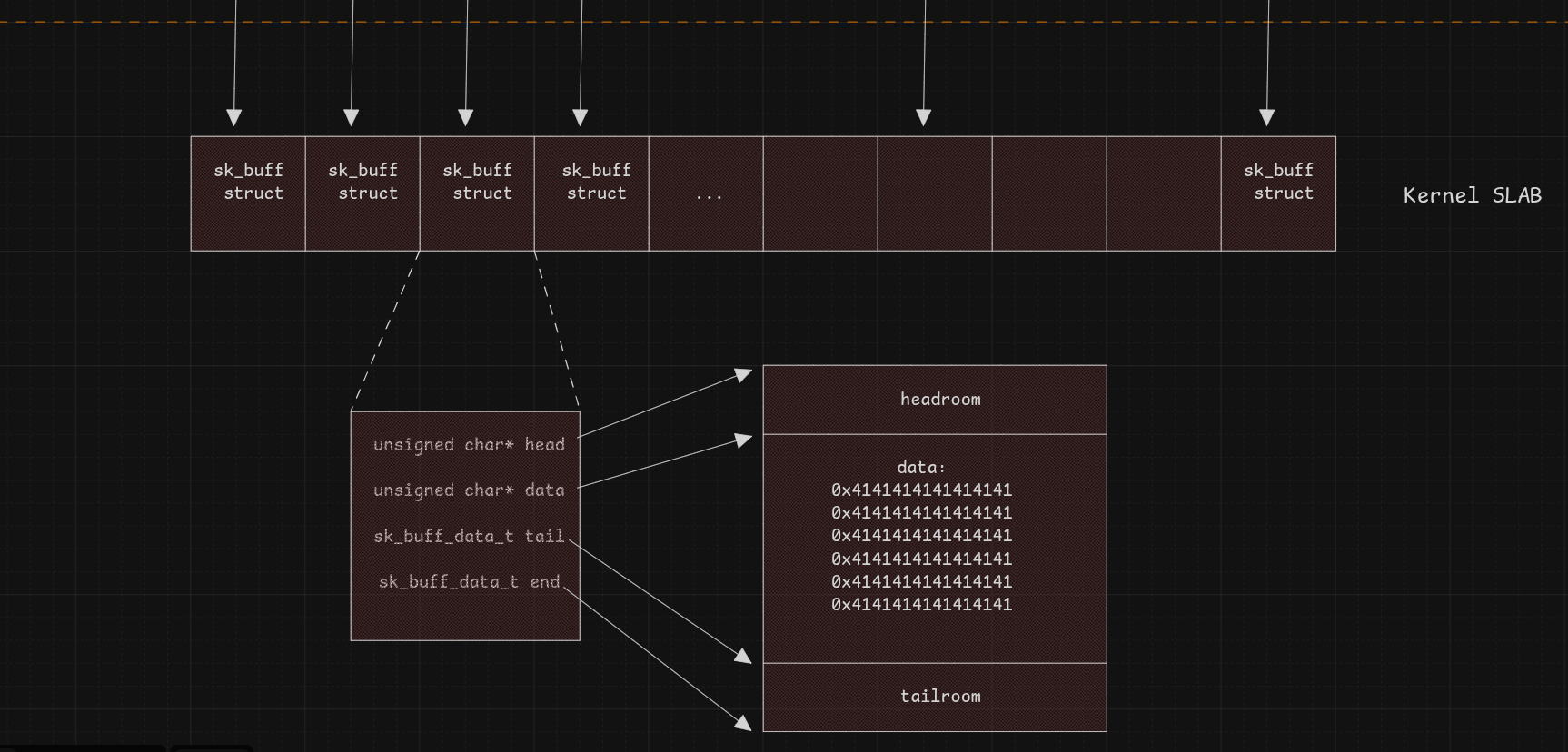
If skb->data is not reclaimed by another allocation, the stored user data will still be present:
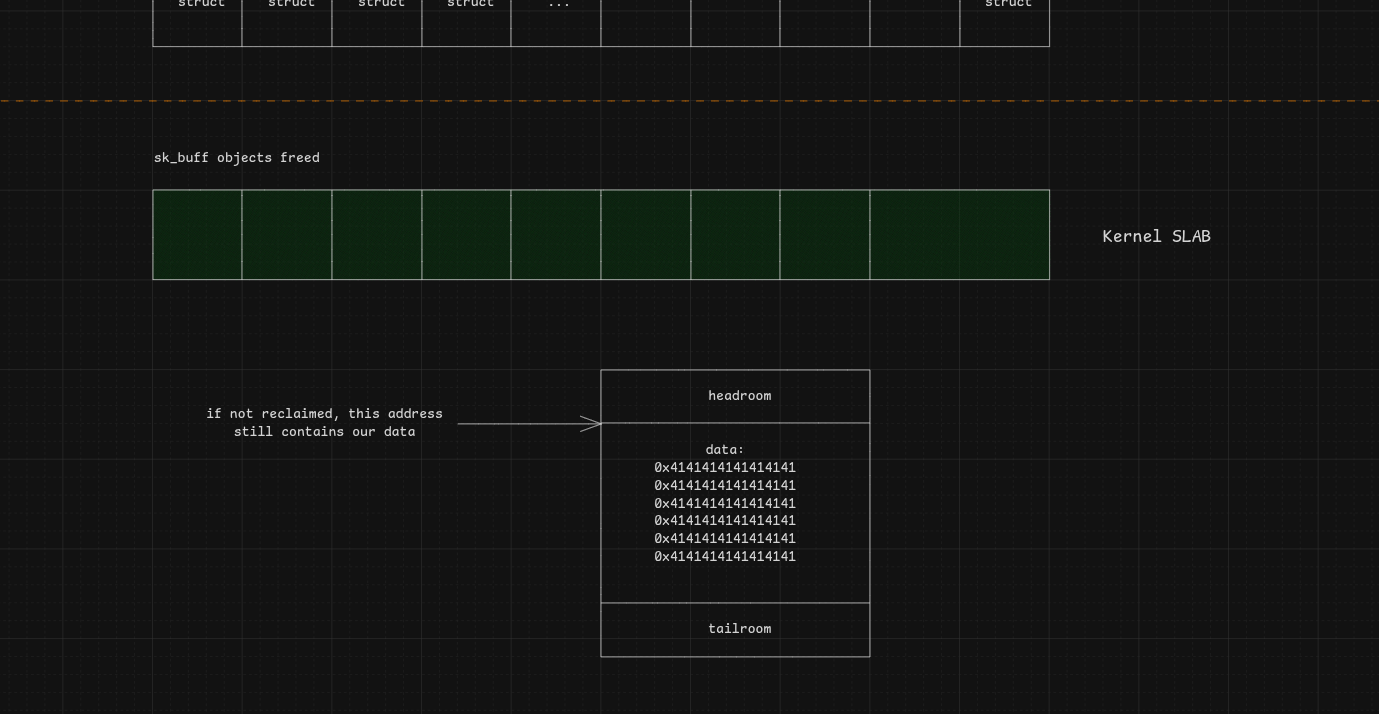
Phase III — Hijacking RIP
We re-spray file objects (or seq_files, or any object with a vtable-like operations pointer), then corrupt their struct file_operations *f_op to point to the remaining skb->data:
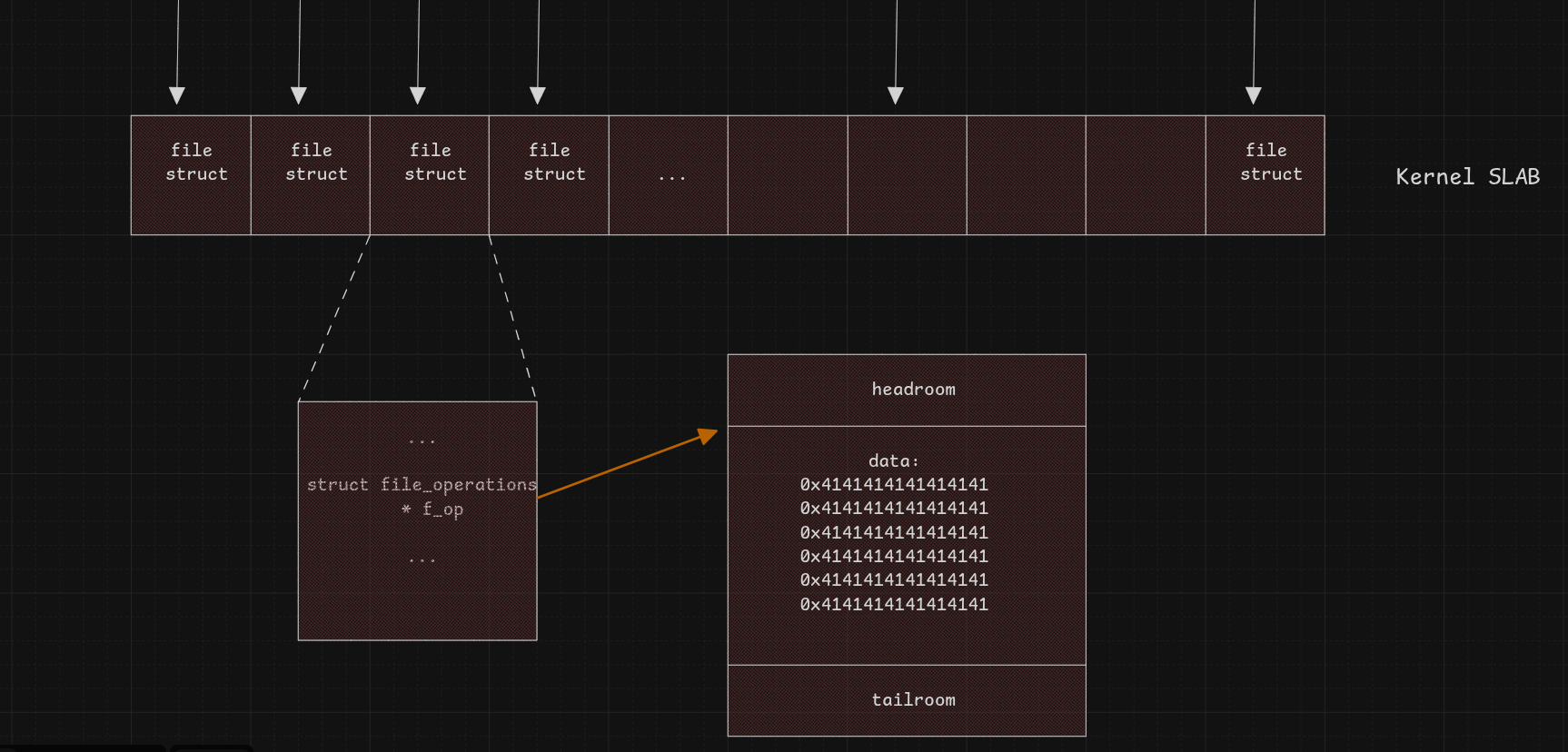
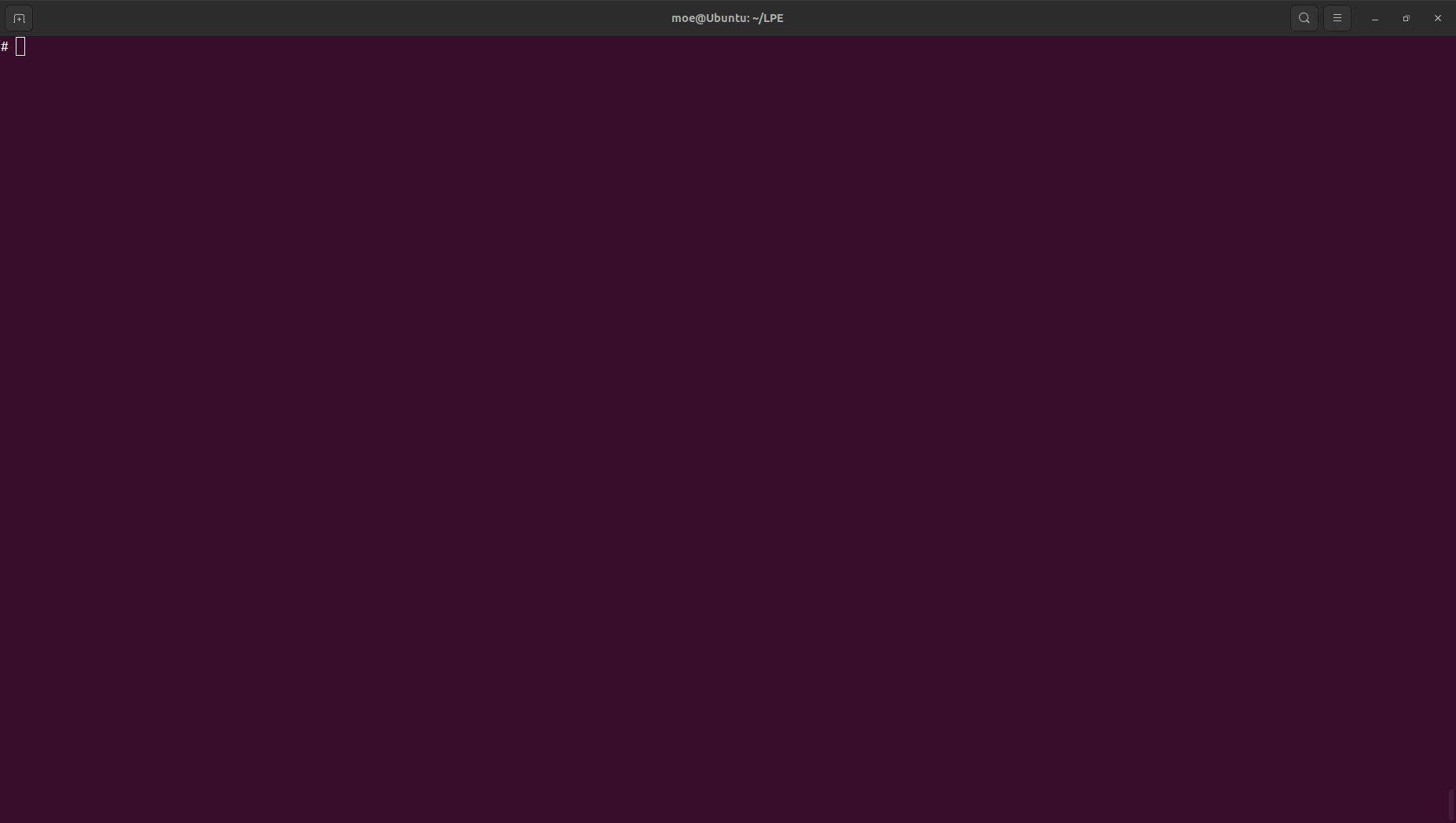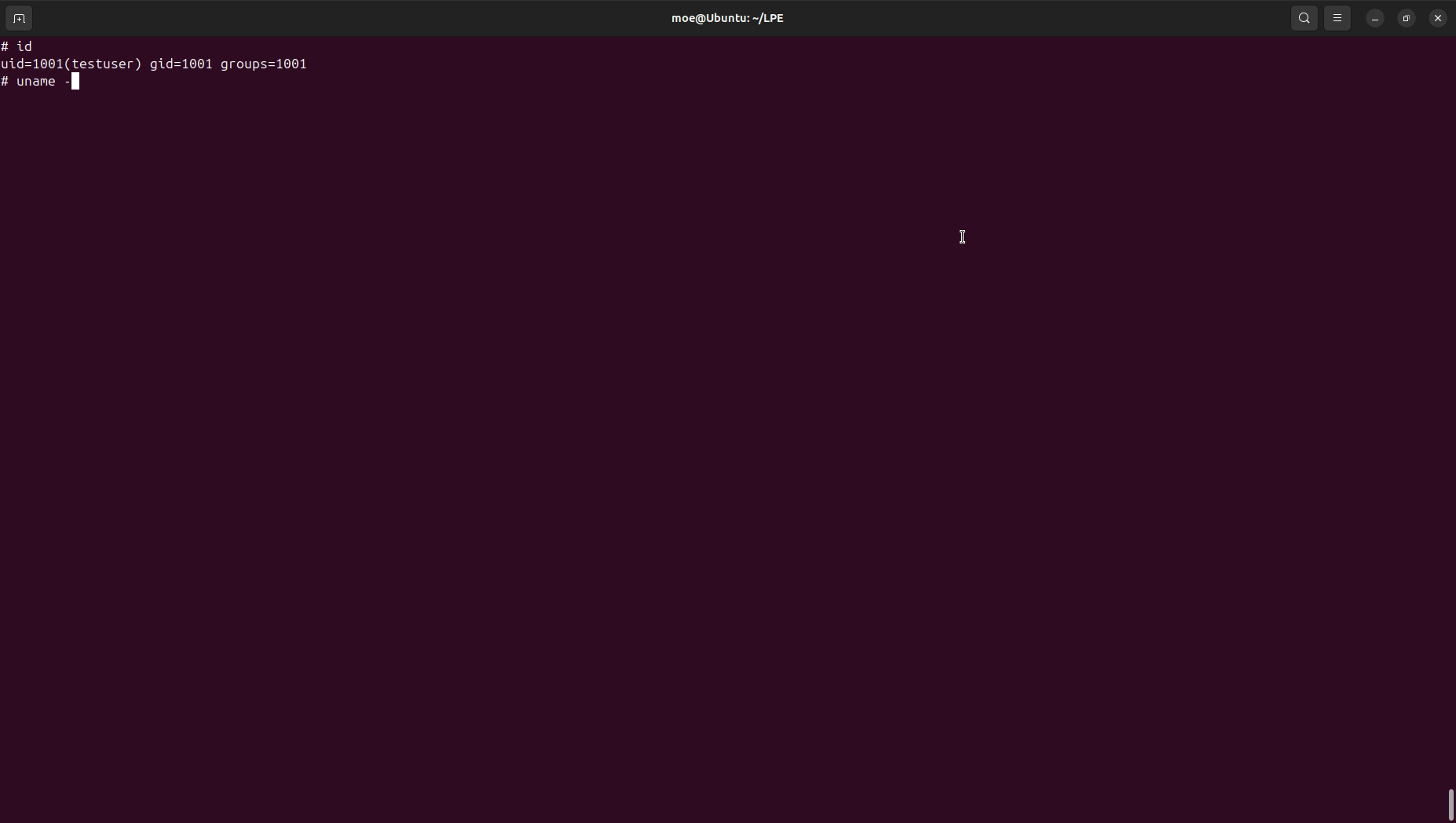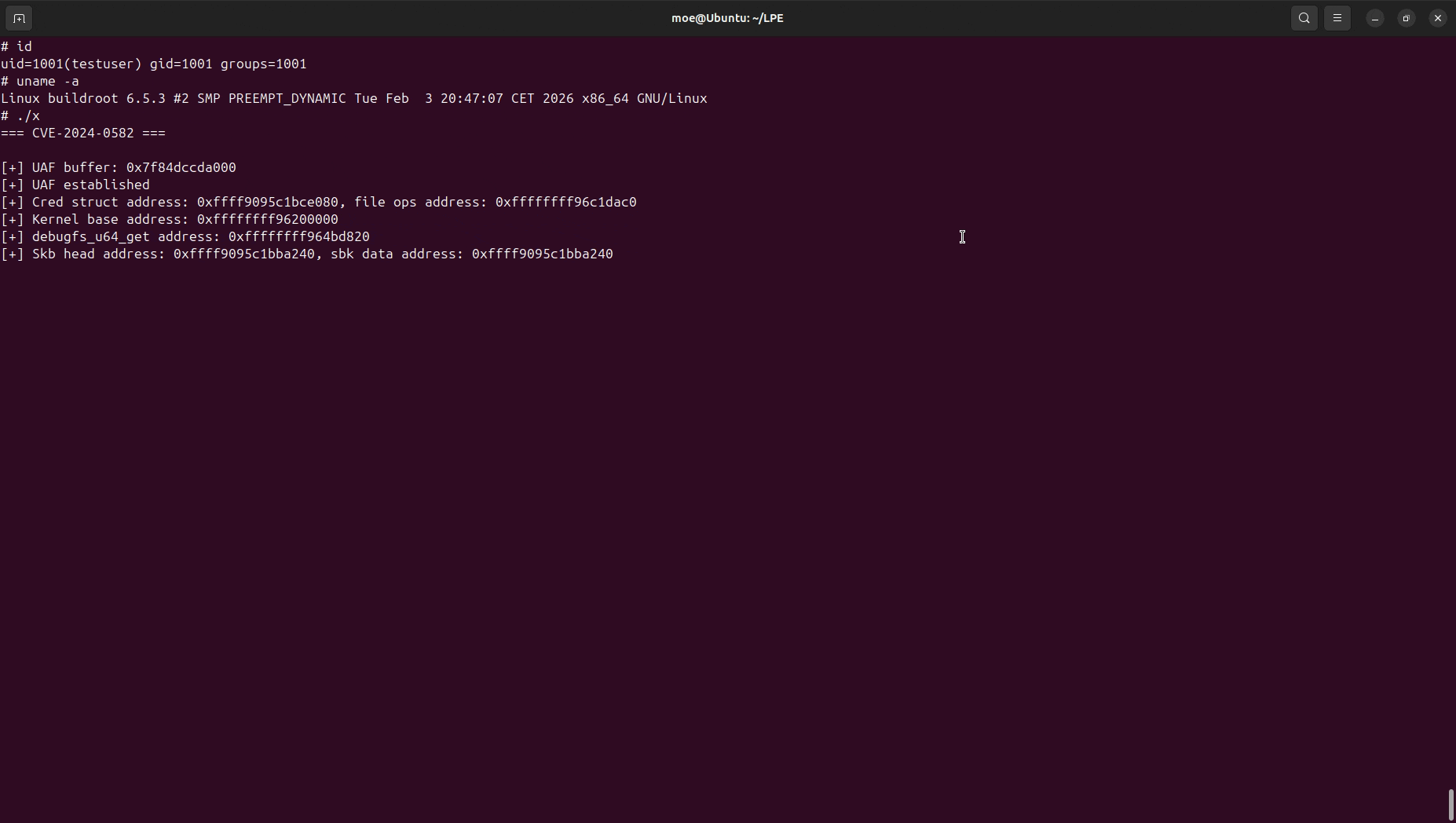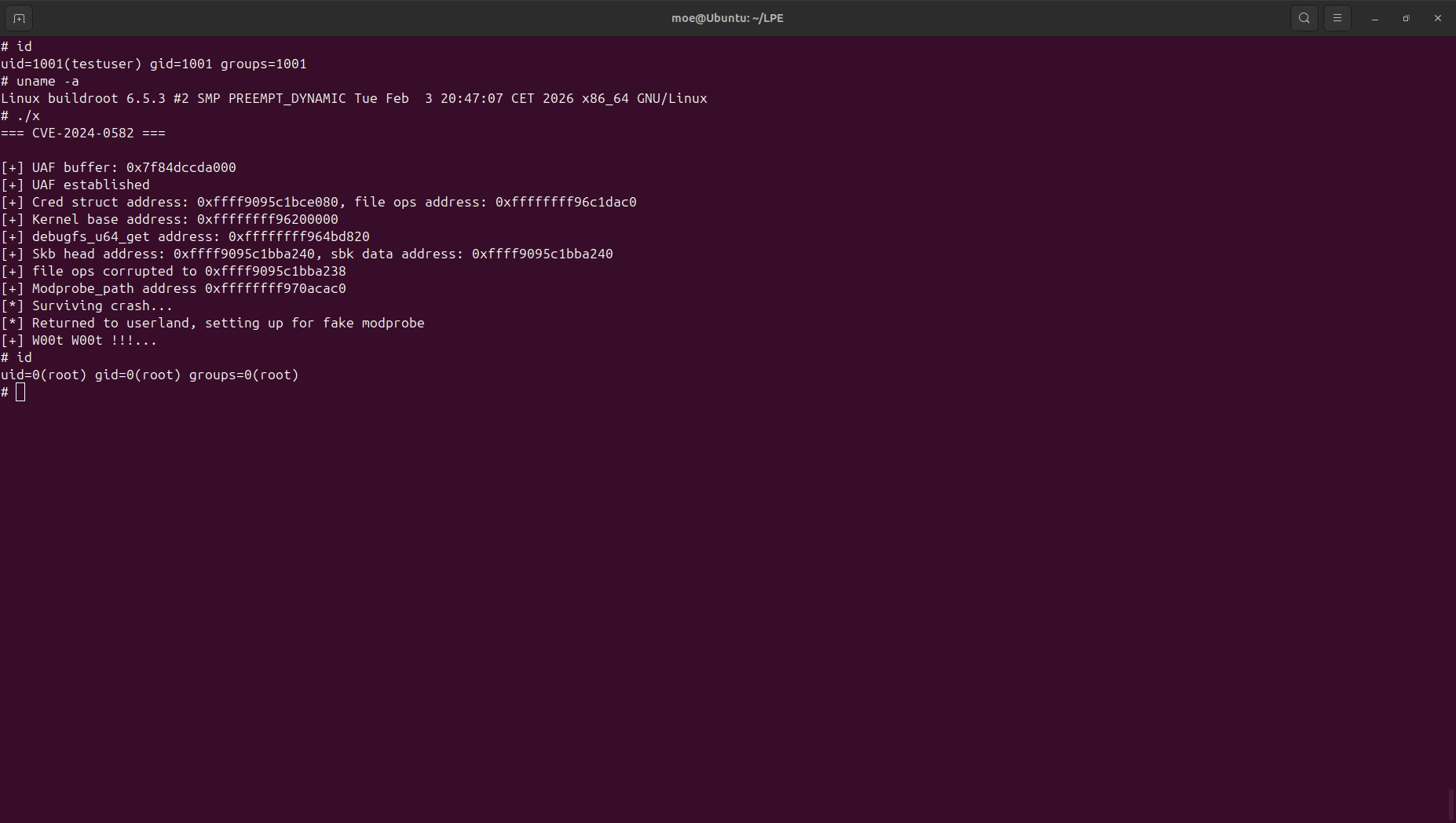
To trigger the hijack, a simple syscall(SYS_lseek, file[i], 0, 0) dereferences the corrupted f_op and calls whatever address is inside. For convenience, RIP is redirected to debugfs_u64_get, which gives an arbitrary write over targets like file->f_cred, modprobe_path, or core_pattern.
Conclusion
That was a walkthrough of io_uring exploitation using CVE-2024-0582 — from the provided-buffer ring UAF primitive through sk_buff spraying to RIP hijacking and arbitrary write. N-days like this one are a great resource for learning and practicing kernel exploitation.
Happy Hacking!