Introduction
This post is some of my early notes on the SLUB allocator.
The kernel heap allocator is an important component responsible for satisfying allocation/de-allocation requests coming from different sources like device drivers, usermode processes, filesystems, etc. These notes discuss only kmalloc and kmem_cache_alloc*, but there are three main memory allocators used by the kernel:
- Page allocator: The underlying allocator for slabs too; it allocates pages of different orders 0, 1, etc.
- Slab allocator: Allocates objects in the form of chunks; it can be thought of as the kernel version of the heap allocator.
- Vmalloc allocator: Used for stacks allocation, as far as I know; like when forking, the kernel allocates the new process’s stack with this.
Even deeper, there’s the Zone allocator (notes are in preparation).
Concretely, kmalloc & kmem_cache_alloc allocate objects like: process descriptors, file structures, network buffers, sockets, etc.
The Linux kernel has 3 flavors of slab allocators: SLAB, SLUB, and SLOB. The SLUB allocator is the default and most widely used, and I cover only SLUB.
SLUB (Simple List of Unused Blocks) is the default kernel memory allocator in Linux, designed as a simplified replacement for the original SLAB allocator. It maintains the performance characteristics of SLAB while providing better maintainability, reduced memory overhead, and improved scalability.

Basic Concepts
The idea of the slab allocator is based on object caching. The slab allocator uses a pre-allocated cache of objects. This cache is created by:
- Reserving some page frames (allocated via the page allocator).
- Dividing these page frames into objects and maintaining some metadata about them.
That being said, a “cache” in this context has a more to it than just a simple reservoir for objects. So let’s see the full picture:
Note: I’m not covering the new sheaves thing for now.
The picture….Tadaaa:
// mm/slab.h - v6.15.9
/*
* Slab cache management.
*/
struct kmem_cache {
#ifndef CONFIG_SLUB_TINY
struct kmem_cache_cpu __percpu *cpu_slab;
#endif
/* Used for retrieving partial slabs, etc. */
slab_flags_t flags;
unsigned long min_partial;
unsigned int size; /* Object size including metadata */
unsigned int object_size; /* Object size without metadata */
struct reciprocal_value reciprocal_size;
unsigned int offset; /* Free pointer offset */
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* Number of per cpu partial objects to keep around */
unsigned int cpu_partial;
/* Number of per cpu partial slabs to keep around */
unsigned int cpu_partial_slabs;
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *object); /* Object constructor */
unsigned int inuse; /* Offset to metadata */
unsigned int align; /* Alignment */
unsigned int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
#ifdef CONFIG_SYSFS
struct kobject kobj; /* For sysfs */
#endif
#ifdef CONFIG_SLAB_FREELIST_HARDENED
unsigned long random;
#endif
#ifdef CONFIG_NUMA
/*
* Defragmentation by allocating from a remote node.
*/
unsigned int remote_node_defrag_ratio;
#endif
#ifdef CONFIG_SLAB_FREELIST_RANDOM
unsigned int *random_seq;
#endif
#ifdef CONFIG_KASAN_GENERIC
struct kasan_cache kasan_info;
#endif
#ifdef CONFIG_HARDENED_USERCOPY
unsigned int useroffset; /* Usercopy region offset */
unsigned int usersize; /* Usercopy region size */
#endif
struct kmem_cache_node *node[MAX_NUMNODES];
};
There are many members and each one has its function. Here are the most basic ones:
name: The name of the cache. There are many caches, each with its own name like:kmalloc-128,cred_jar, custom ones, etc.object_size: The size of objects in the cache.list: A doubly linked list of all the slab caches.
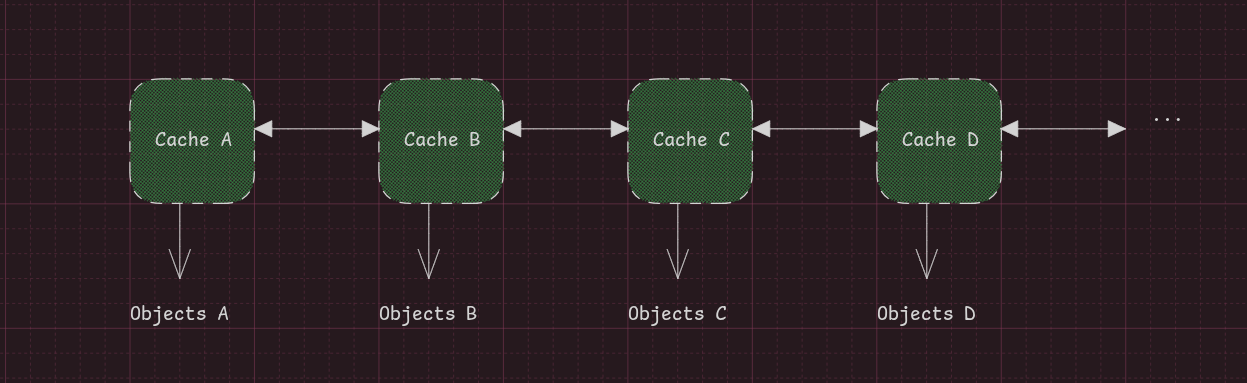
Per-CPU Slab
Now that we have a sense of what a cache is, the question is: how does object allocation work?
Allocations done through kmalloc or kmem_cache_alloc* pick available chunks from the cache, but where exactly?
The answer is struct kmem_cache_cpu __percpu *cpu_slab; — a per-CPU object, meaning that each CPU core has its own state to pick from.
Note: If we pin thread A to CPU 0 and thread B to CPU 1 simultaneously, the first allocates from the slabs cached in CPU 0 and the second from slabs cached in CPU 1.
struct kmem_cache_cpu {
union {
struct {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
};
freelist_aba_t freelist_tid;
};
struct slab *slab; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct slab *partial; /* Partially allocated slabs */
#endif
local_lock_t lock; /* Protects the fields above */
#ifdef CONFIG_SLUB_STATS
unsigned int stat[NR_SLUB_STAT_ITEMS];
#endif
};
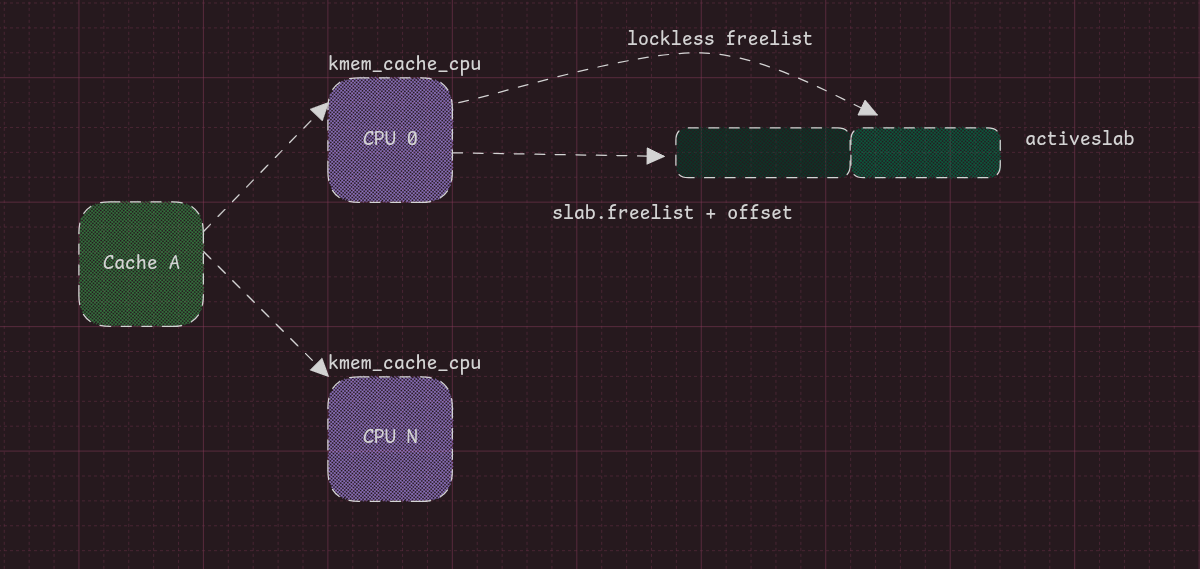
freelist: The fast path (lockless). It points to freed chunks in the active slab.slab: Points to what we call the active slab — the set of pages that contain freed chunks.
The freelist is the fastest path: if it’s pointing to a freed object, an allocation returns it. Otherwise, it falls through to slab, the active slab.
A slab is one or more compound pages that are split into objects:
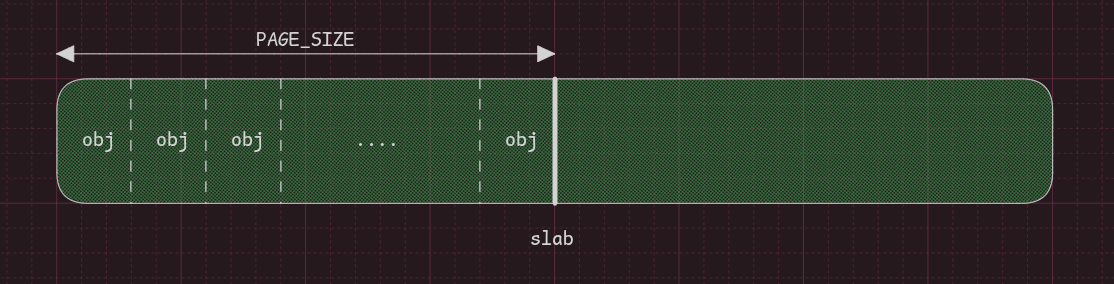
The paging is expressed in terms of order: if a slab has only 1 page, we say it has order 0, and so on.
The struct slab
Note: “the SLAB allocator” vs “the slab” —
The SLAB allocatoris a design/paradigm of memory allocation, whereasthe slabis a data structure.
/* Reuses the bits in struct page */
struct slab {
unsigned long __page_flags;
struct kmem_cache *slab_cache; // [1]
union {
struct {
union {
struct list_head slab_list; // [2]
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct {
struct slab *next; // [2.5]
int slabs; /* Nr of slabs left */
};
#endif
};
/* Double-word boundary */
union {
struct {
void *freelist; // [3] /* first free object */
union {
unsigned long counters;
struct {
unsigned inuse:16;
unsigned objects:15;
/*
* If slab debugging is enabled then the
* frozen bit can be reused to indicate
* that the slab was corrupted
*/
unsigned frozen:1;
};
};
};
};
// [...]
#endif
};
As dense as this structure looks, only a few details are relevant:
- [1] is a pointer to the cache the slab belongs to.
- [2] & [2.5]: the slab has a next pointer/list so the allocator can walk through the slabs.
- [3] is the pointer to the second freelist, i.e. the 2nd fastest path.
It should be noted that the lockless freelist and active slab freelist do not intersect, although they live in the same slab. Another thing is that the lockless freelist serves as a bridge between cores for objects to move around.
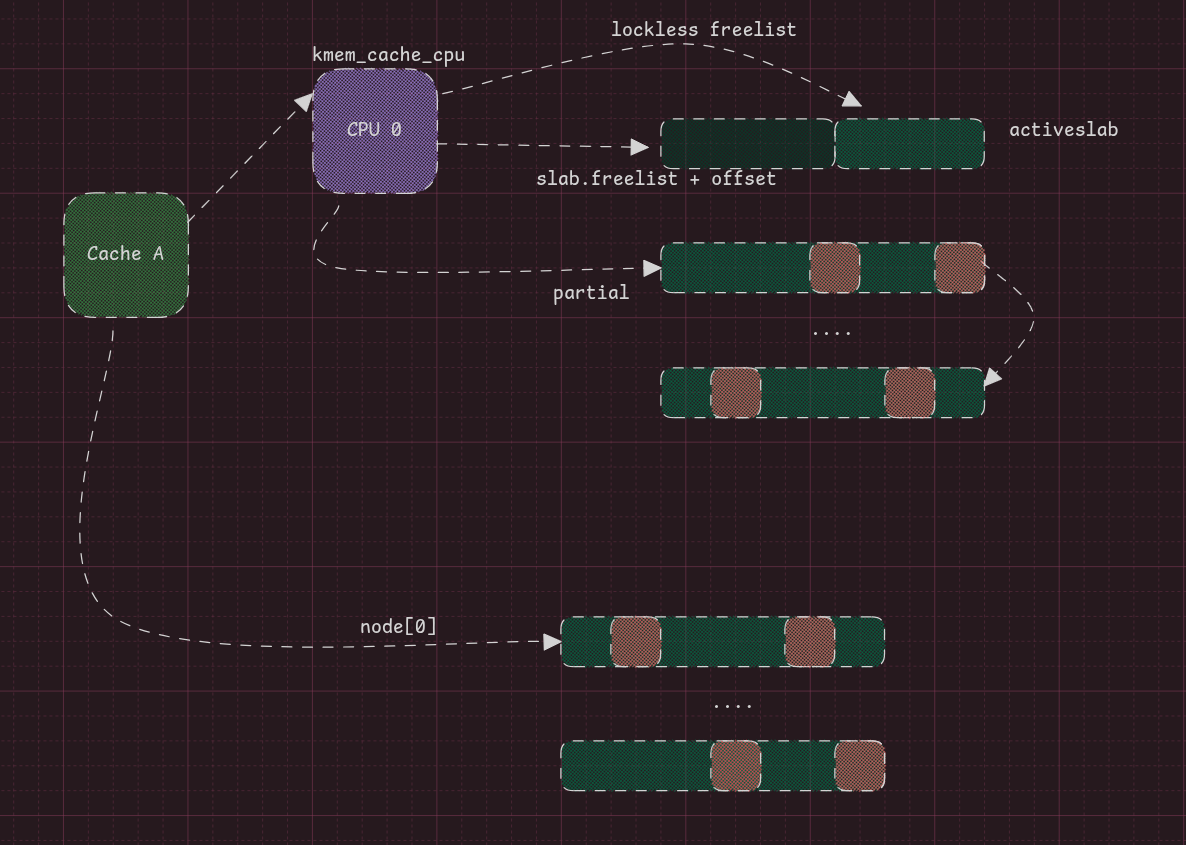
Partial Lists and Full Slabs
What happens when you free from a full slab?
A slab is full when all its elements are allocated; in that case, it becomes untracked by the cache (except in some debug configs). However, when an element of it is freed, the whole slab that the freed object belongs to is placed into a partial list. So every non-full slab that is not the active slab is placed into some partial list — either the per-CPU one, or the node one.
Note that the per-CPU list has limits; to verify:
cat /sys/kernel/slab/<cache_name>/cpu_partial
This corresponds to the cpu_partial_slabs member in the cache structure.
If the per-CPU list hits this limit:
- It purges completely free slabs back into the page allocator — this behaviour is exploited in Cross-Cache attacks.
- It moves the others into the per-node partial list.
These slabs go back and forth between the active slab and the partial lists as objects are allocated and freed.
Conclusion
These are introductory notes. I’ll dive deeper into more interesting things like Cross-Cache and Cross-CPU attacks; the new sheaves mechanism needs to be understood too.
References
https://blogs.oracle.com/linux/post/linux-slub-allocator-internals-and-debugging-1
https://events.static.linuxfound.org/images/stories/pdf/klf2012_kim.pdf
https://sam4k.com/linternals-memory-allocators-0x02/
https://events.static.linuxfound.org/sites/events/files/slides/slaballocators-japan-2015.pdf