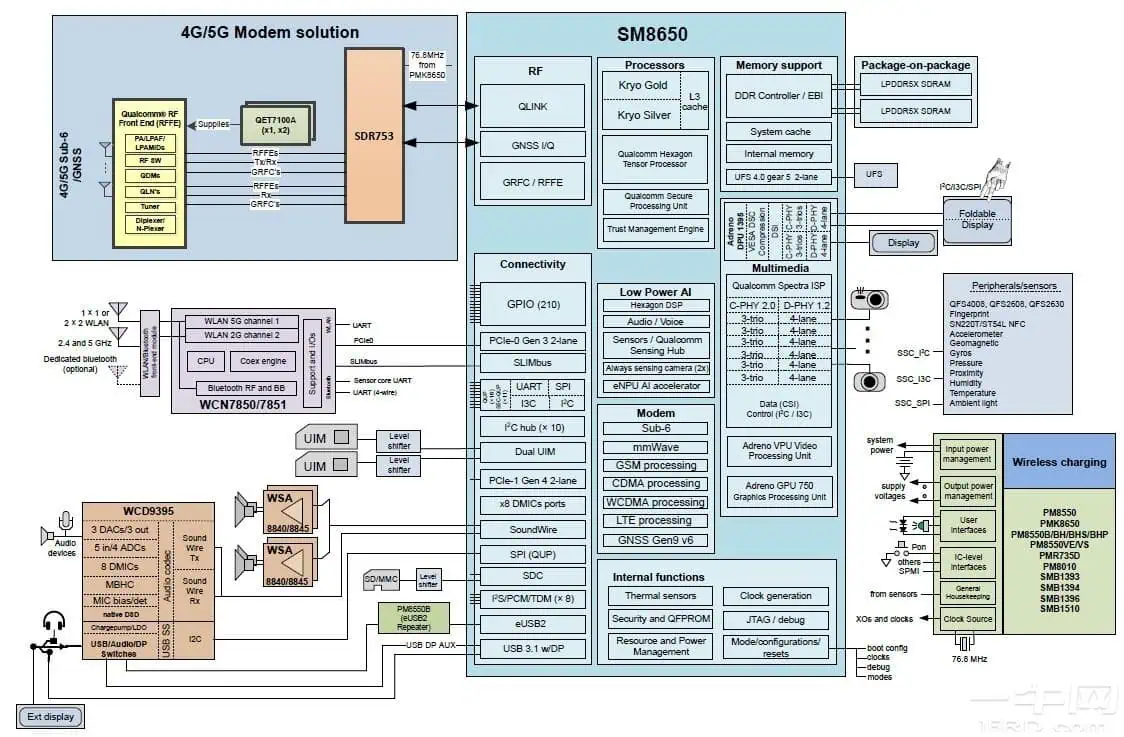
Starting my journey in Mobile Vendor Chips internals & VR, i chose Qualcomm SoC since it is a very well known and a dominant brand in the phone space, and of course, a cherished target among exploit developers in many angles. However, it has a complex architecture and massive codebase; if we take for example the Snapdragon SoCs, they have: a CPU, Andreno GPU, many DSPs, AI accelerators(NPU), sensors, video processors…etc and each one of these has its own microprocessor, firmware and Operating System; so, even to start out, one should at least have a big picture before blindly diving into one specific thing; hence my goal is to establish some foundation.
 _source: https://www.androidheadlines.com/2024/10/snapdragon-8-elite-leaked.html
_source: https://www.androidheadlines.com/2024/10/snapdragon-8-elite-leaked.html
The threat model to my knowledge has at least 4 categories:
- LPEs in the Application Processor, which is probably the most common one; many browser sandbox escapes and straight LPEs happen from restricted apps that have access to devices
/dev/*or some/proc/*like/dev/kgsl-3d0or/dev/vpu…etc, where IOCTLs give a rich attack surface into the AP-side GPU / NPU / VPU…etc drivers; this is standard kernel exploitation if we put aside the debugging issues. - RCEs: Remote Code Execution is a very known thing is AP userspace like in WhatApp, Browser, and all 0/1-clicks stuff. But, here we have another kind of RCE, which is from Cellular Networking in 3/4/5G that we use in our mobile phones to get internet or make calls. In modern chips, a dedicated processor, called Baseband Processor or BP, is used to handle the operations on the Network traffic; on Qualcomm chips, the mDSP is the BP where on top of the RTOS kernel, userspace task(s) that handle the actual baseband logic maybe have exploitable vulnerabilities just like in regular userpace programs, and thus resulting in an RCE on the BP; However, an RCE in this case does not give access to the other DSPs or the CPU system, unless chained with other bugs to pivot.
- bootloader unlocking: Unlocking the bootloader is crucial for security search, and this is done using hardware ..etc etc.
- TrustZone hacking.
Qualcomm GPU - Adreno
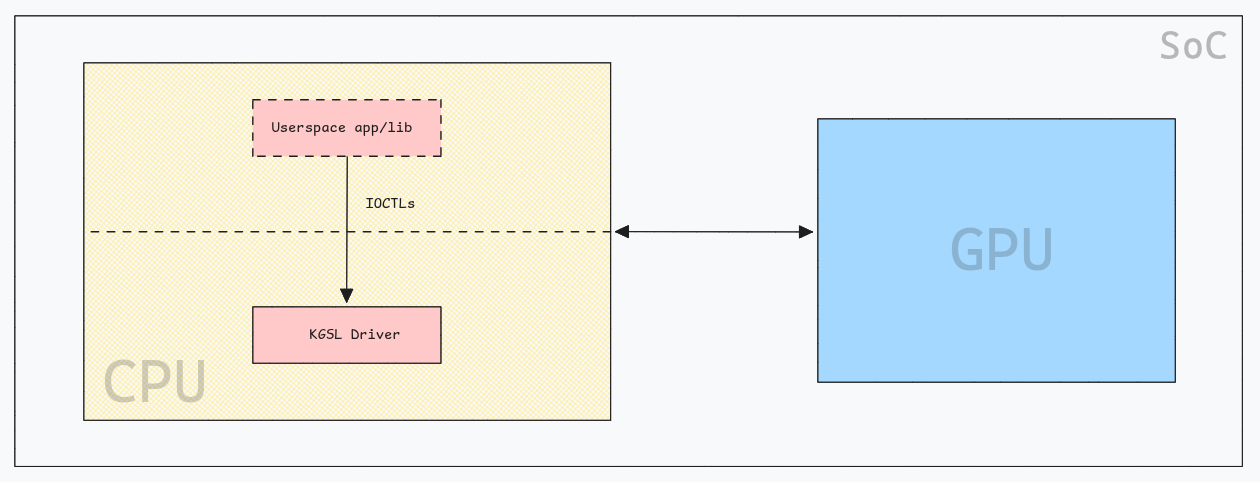
KGSL:
_sources: https://git.codelinaro.org/clo/la/platform/vendor/qcom/opensource/graphics-kernel
Kernel Graphics Support Layer or, KGSL, serves as the kernel-mode driver for the Adreno GPU in the CPU (the GPU hardware itself runs its own drivers in its own CPU). As the official documentation says: "the primary function of the KGSL driver is to submit commands generated by the Adreno user-mode driver to the Adreno GPU for processing". The “user-mode driver” just means a userspace .so library that simplifies the work for the user/program like libvulkan_adreno.so, libGLESv1_CM_adreno.so…etc. Additionally, the KGSL driver communicates with the GMU(Graphics Management Unit) to ensure proper state management.
This driver can be thought of as an API for the Host system to control the GPU execution through many IOCTLs (in kgsl_ioctl.c):
IOCTL_KGSL_DEVICE_GETPROPERTY
IOCTL_KGSL_DEVICE_WAITTIMESTAMP_CTXTID
IOCTL_KGSL_SUBMIT_COMMANDS
IOCTL_KGSL_MAP_USER_MEM
IOCTL_KGSL_SHAREDMEM_FROM_PMEM
IOCTL_KGSL_GPUMEM_FREE_ID
// [...]
Inside the GPU:
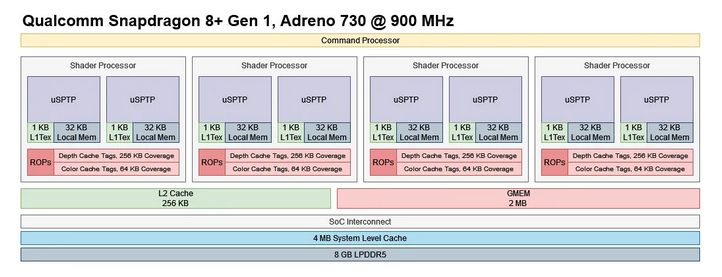 _source: https://chipsandcheese.com/p/correction-on-qualcomm-igpus
_source: https://chipsandcheese.com/p/correction-on-qualcomm-igpus
Well, the GPU is a big complex piece of hardware & software and it’s certainly beyond my understanding; it is interesting to note though that it has many processors in it, and not only one: Command Processor, Multiple Shader Processors, GMU Processor; and each one has its microcode & firmware.
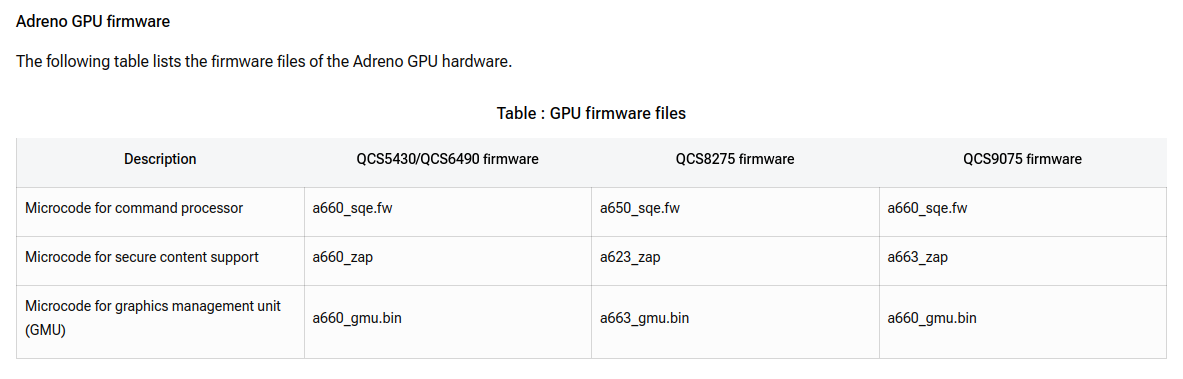 _source: https://docs.qualcomm.com/doc/80-70017-19/topic/graphics-overview.html
_source: https://docs.qualcomm.com/doc/80-70017-19/topic/graphics-overview.html
DSPs
To offload heavy operations on the CPU, the Qualcomm SoC has integrated many DSPs (Digital Signal Processor) like aDSP(application DSP), cDSP(compute DSP) or mDSP(modem DSP) for baseband; each DSP runs QuRT1 which is a Qualcomm’s proprietary RTOS.
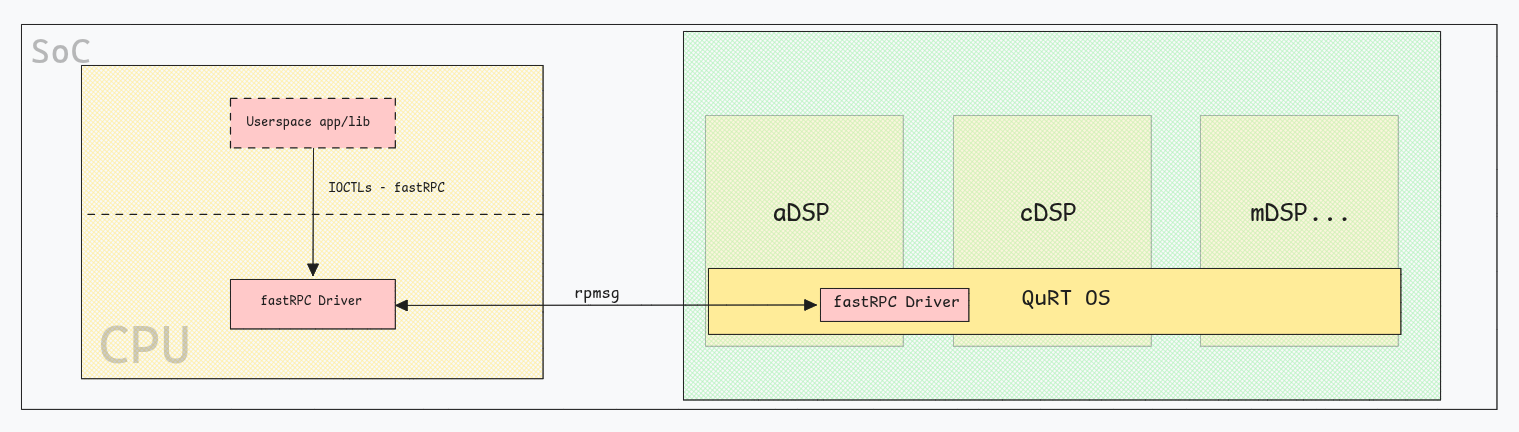
Their firmware is verified by the TEE before the DSPs starting.
The DSPs firmware files are available to download either from the net or locally in /lib/firmware/qcom:

The communication CPU <-> DSP is done through shared memory and an RPC protocol, since the DSPs need to fetch the CPUs requests, and likewise the CPU needs to grab the results.
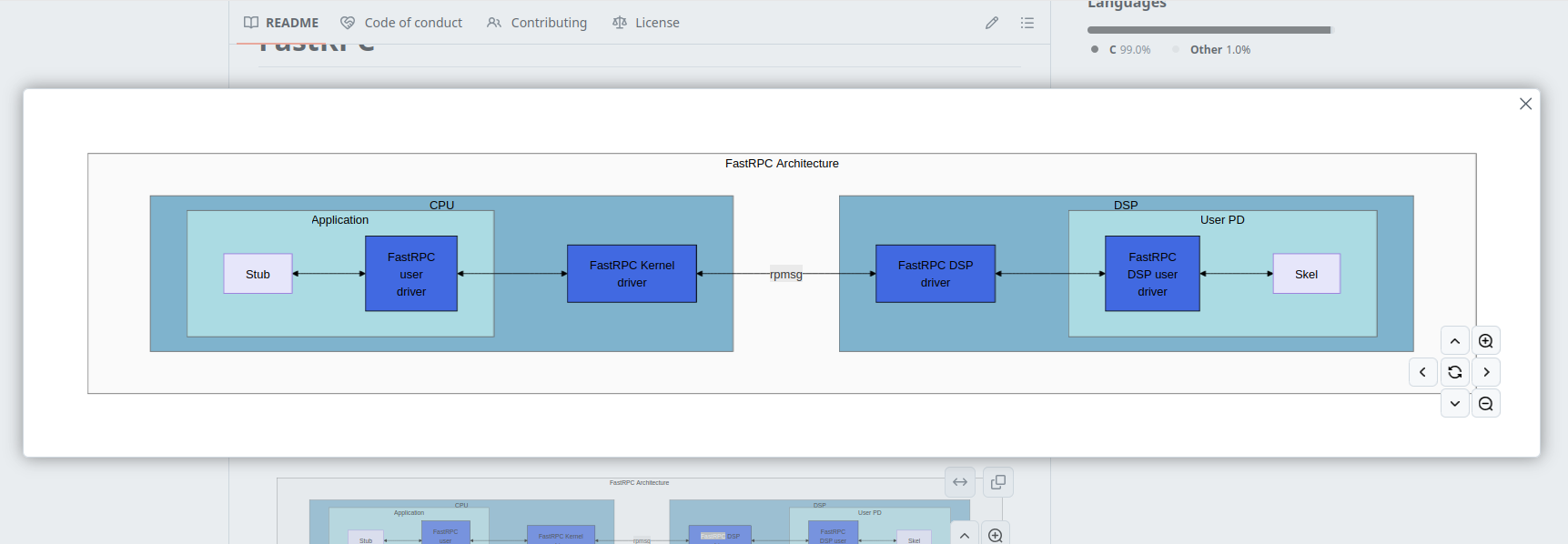
As documented in fastRPC repo :
Workflow:
- The CPU process calls the stub version of the function. The stub code converts the function call to an RPC message.
- The stub code internally invokes the FastRPC framework on the CPU to queue the converted message.
- The FastRPC framework on the CPU sends the queued message to the FastRPC DSP framework on the DSP.
- The FastRPC DSP framework on the DSP dispatches the call to the relevant skeleton code.
- The skeleton code un-marshals the parameters and calls the method implementation.
- The skeleton code waits for the implementation to finish processing, and, in turn, marshals the return value and any other output arguments into the return message.
- The skeleton code calls the FastRPC DSP framework to queue the return message to be transmitted to the CPU.
- The FastRPC DSP framework on the DSP sends the return message back to the FastRPC framework on the CPU.
- The FastRPC framework identifies the waiting stub code and dispatches the return value.
- The stub code un-marshals the return message and sends it to the calling User mode process.
Concepts:
| Term | Description |
|---|---|
| Application | User mode process that initiates the remote invocation |
| Stub | Auto-generated code that takes care of marshaling parameters and runs on the CPU |
| FastRPC user driver on CPU | User mode library that is used by the stub code to do remote invocations |
| FastRPC Kernel Driver | Receives the remote invocations from the client, queues them up for transport to the DSP side over rpmsg, and then waits for the response after signaling the remote side |
| rpmsg | Remote Processor Messaging is the transport mechanism used between the CPU-side FastRPC kernel driver and the DSP-side FastRPC driver to exchange FastRPC requests and responses |
| FastRPC DSP Driver | Dequeues the messages received over rpmsg from the FastRPC kernel driver and dispatches them for processing |
| FastRPC user driver on DSP | User mode code that includes a shell executable to run in the user protection domain (PD) on the DSP and complete the remote invocations to the skel library |
| Skel | Auto-generated code that un-marshals parameters and invokes the user-defined implementation of the function that runs on the DSP |
| User PD | User protection domain on the DSP that provides the environment to run the user code |
QuRT OS & Hexagon
On every DSP, QuRT (Qualcomm Real-Time) OS is running; and DSP’s processor has the Hexagon architecture. This choice of running the baseband on its own separate CPU and not the ARM AP, is because it is time sensitive and needs to be responsive quasi-instantly; the usage of Real-Rime OS has the same goal, since this kind of OS has deterministic microsecond-level scheduling, where higher priority threads preempt lower priority ones.
Though, there are not too many information QuRT, since it is a proprietary OS, i hope i am going to write more about this in the near future.
Moving onto hexagon architecture…
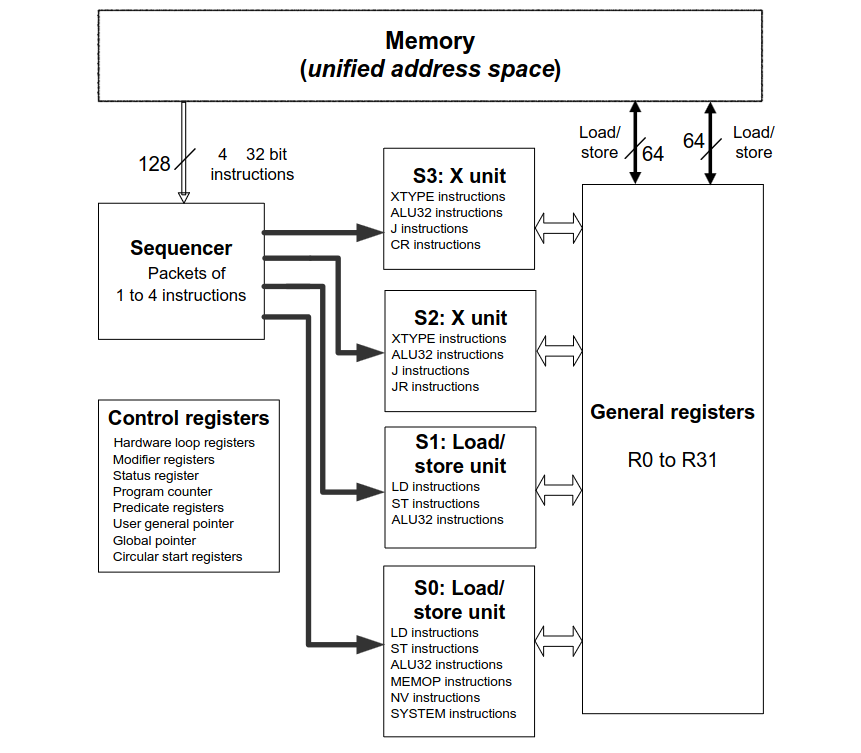 _source: https://docs.qualcomm.com/doc/80-N2040-53/80-N2040-53.pdf
_source: https://docs.qualcomm.com/doc/80-N2040-53/80-N2040-53.pdf
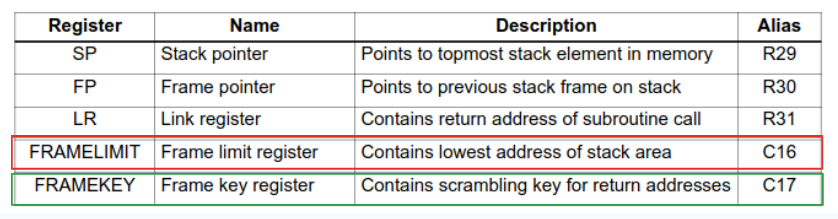
There are 4 executions units S0 to S3 each one handles specific instructions; the Sequencer grabs to 4 instructions(32 bit instructions) from RAM, and feeds the execution units. This architecture has 2 types of registers:
- General Purpose Register(32-bit): R0 to R28 that are used for scalar/vector arithmetic and different other general operations like storing operands and memory addresses for instructions. From R29 to R31, aliased as SP, FP and LR respectively, are used for execution, where SP is Stack Pointer that points to the top of the stack(as in x86), FP points to the current stack frame of the current task(like RBP in x86), and LR stores the return address of a subroutine call.
 _source: https://docs.qualcomm.com/doc/80-N2040-53/80-N2040-53.pdf
_source: https://docs.qualcomm.com/doc/80-N2040-53/80-N2040-53.pdf
- Control Registers: these likewise 32-bit register that provide access to the processor’s features such as PC (Program Counter, RIP in x86), hardware loops etc.
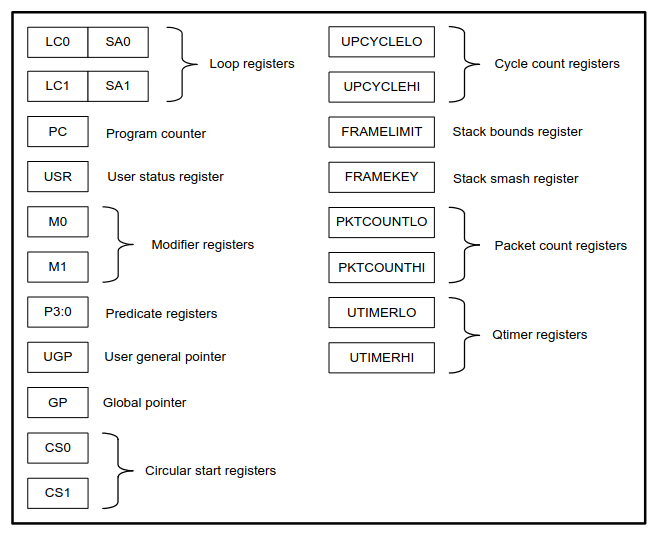 _source: https://docs.qualcomm.com/doc/80-N2040-53/80-N2040-53.pdf
_source: https://docs.qualcomm.com/doc/80-N2040-53/80-N2040-53.pdf
Stack Structure:
The Stack as any many other architectures grows downwards, and SP points to its top(must be 8-byte aligned). Each subroutine(function call) creates its own frame with is pointed to by FP and contains its local variables. LR & FP are saved as the return address after the subroutine completes just, and the frame pointer of the caller routine respectively.
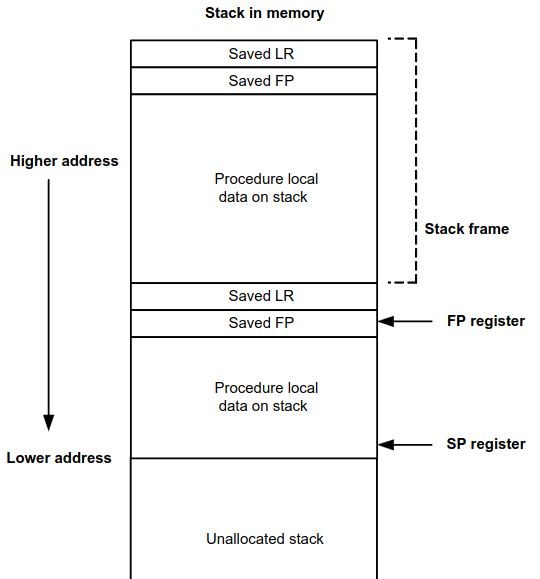 _source: https://docs.qualcomm.com/doc/80-N2040-53/80-N2040-53.pdf
_source: https://docs.qualcomm.com/doc/80-N2040-53/80-N2040-53.pdf
Security wise, execution hijacking though Saved LR corruption is the most famous exploitation technique; and Hexagon seems to implement a protection mechanism against that:
 _source: https://docs.qualcomm.com/doc/80-N2040-53/80-N2040-53.pdf
_source: https://docs.qualcomm.com/doc/80-N2040-53/80-N2040-53.pdf
- Using FRAMEKEY, the value of LR is simply XOR’d with it before saving upon a subroutine call:
Saved LR <- {FRAMEKEY} XOR {LR}. - FRAMELIMIT is simply a bound limit that SP is checked against so it doesn’t go beyond this lower limit.
This is done in this prologue section:
allocframe(#u11:3) ->
This instruction is used after a call. It first XORs the values in
LR and FRAMEKEY, and pushes the resulting scrambled
return address and FP to the top of the stack.
Next, it subtracts an unsigned immediate from SP to allocate
room for local variables. If the resulting SP is less than
FRAMELIMIT, the processor raises exception 0x27.
Otherwise, SP is set to the new value, and FP is set to the
address of the old frame pointer on the stack.
The immediate operand as expressed in assembly syntax
specifies the byte offset. This value must be 8-byte aligned.
The valid range is from 0 to 16 KB.
In the Epilogue : dealloc_return is the equivalent of ret in x86
dealloc_return ->
Subroutine return with stack frame deallocate.
Perform the **deallocframe** operation, and then perform the
subroutine return (Section 8.3.3) to the target address
loaded from LR by deallocframe.
deallocframe :
deallocframe ->
Deallocate stack frame.
Use this instruction before a return to free a stack frame. It
first loads the saved FP and LR values from the address at
FP, and XORs the restored LR with the value in FRAMEKEY
to unscramble the return address. SP is then pointed back to
the previous frame.
Closing Word:
This is meant be to an introduction to this very interesting topic; i hope there will be more to come soon… stay tuned.
References:
- https://www.freecodecamp.org/news/qurt-the-real-time-os-inside-your-phone-s-processor-full-handbook/
- https://androidoffsec.withgoogle.com/posts/a-technical-deep-dive-into-cve-2024-23380-exploiting-gpu-memory-corruption-to-android-root/
- https://fosdem.org/2026/events/attachments/SXNNMZ-snapdragon_8_gen_3_mainline_from_day-1_patches_to_product_reality/slides/267187/fosdem_20_bqxykvk.pdf
- https://www.youtube.com/watch?v=U_awEXRp72k
- https://census-labs.com/media/attacking-hexagon-recon19.pdf
- https://zerodayengineering.com/research/slides/BH2025_ReverseEngineeringHexagonISDB.pdf