Everybody knows that iOS pwn is (real) hard for userland(and kernel too obviously); but folks, you should know that even Android is catching up now, so don’t worry, you can keep your Pixel 18 Pro Max ;-) LOLL
This post covers the default userland hardened allocator for Android called: scudo.
All pwners, and i fact all Linux users, have worked with the old good glibc’s ptmalloc. this one is very documented and there’s even an excellent github repo how2heap that illustrates attacks(Houses) on each ptmalloc version. Though, this new allocator is much less documented, although there’s some documentation here and there link 1, link 2, link 3 & link4. But these all predate 2024, so in this post i try to give a fresh 2026 take.
The goal here is not to dump every single source file verbatim, but to rebuild enough of the control flow that the allocator stops feeling like a black box. If you can follow how malloc becomes a primary or secondary allocation, and how free either goes back to a local cache or gets delayed in quarantine, then most of Scudo’s higher-level hardening choices start making sense.
Basics:
Since Android 11, Scudo has become the default allocator, and before that, it was jemalloc (source). Scudo is a part of LLVM’s compiler-rt project, and resides in compiler-rt/lib/scudo/standalone. So let’s start digging its functionalities.
ALLOCATION PATH - MALLOC:
By retracing the path of how a simple allocation request is made, we can get more intuition on how things work, so let’s see how a simple malloc is handled:
// scudo/standalone/wrappers_c.cpp
// [...]
#if defined(SCUDO_PREFIX_NAME)
#define SCUDO_PREFIX(name) CONCATENATE(SCUDO_PREFIX_NAME, name)
#define SCUDO_ALLOCATOR_STATIC static
#else
#define SCUDO_PREFIX(name) name
// [...]
INTERFACE WEAK void *SCUDO_PREFIX(malloc)(size_t size) {
void *Ptr = Allocator.allocate(size, scudo::Chunk::Origin::Malloc,
SCUDO_MALLOC_ALIGNMENT); // [1]
reportAllocation(Ptr, size); // [2]
return scudo::setErrnoOnNull(Ptr);
}
It does two things:
At [1], Allocator.allocate(...) does the actual allocation and returns a pointer as usual; and at [2] in case flag SCUDO_ENABLE_HOOKS is activated, it tracks this new allocation as the last allocated address.
That makes wrappers_c.cpp a very thin front-end: the wrapper mostly normalizes the C ABI, then immediately hands control to the real allocator logic in combined.h. In other words, if we want to understand the interesting behavior, almost all roads lead to Allocator.allocate(...).
Let’s focus on [1]; it’s a lengthy function, so we go step by step:
// scudo/standalone/combined.h
NOINLINE void *allocate(uptr Size, Chunk::Origin Origin,
uptr Alignment = MinAlignment,
bool ZeroContents = false) NO_THREAD_SAFETY_ANALYSIS {
initThreadMaybe(); // [1.1]
/*
ALWAYS_INLINE void initThreadMaybe(bool MinimalInit = false) {
TSDRegistry.initThreadMaybe(this, MinimalInit);
}
*/
// [...]
Shared vs Exculsive TDSs
This calls function initThreadMaybe(), which seems to be a method for used by the shared model and also by the exclusive one:
// scudo/standalone/combined.h
// [...]
ALWAYS_INLINE void initThreadMaybe(bool MinimalInit = false) {
TSDRegistry.initThreadMaybe(this, MinimalInit);
}
// scudo/standalone/tsd_shared.h
ALWAYS_INLINE void initThreadMaybe(Allocator *Instance,
UNUSED bool MinimalInit) {
if (LIKELY(getCurrentTSD()))
return;
initThread(Instance);
}
// scudo/standalone/tsd_exclusive.h
ALWAYS_INLINE void initThreadMaybe(Allocator *Instance, bool MinimalInit) {
if (LIKELY(State.InitState != ThreadState::NotInitialized))
return;
initThread(Instance, MinimalInit);
}
A global state is maintained as State.InitState and there 3 states:
NotInitialized = 0,
Initialized,
TornDown,
The initialization is done if it is not ThreadState::NotInitialized;
TSDregisteryExT maintains a global state member static thread_local ThreadState State; which is common to all procecess / Threads and allocation. The comment in following initThread(...) confirms that:
// scudo/standalone/tsd_exclusive.h
// Using minimal initialization allows for global initialization while keeping
// the thread specific structure untouched. The fallback structure will be
// used instead.
NOINLINE void initThread(Allocator *Instance, bool MinimalInit) {
initOnceMaybe(Instance);
if (UNLIKELY(MinimalInit)) // [3]
return;
CHECK_EQ(
pthread_setspecific(PThreadKey, reinterpret_cast<void *>(Instance)), 0);
ThreadTSD.init(Instance);
State.InitState = ThreadState::Initialized;
Instance->callPostInitCallback();
}
Only a minimal init is done when MinimalInit is set; as the comment says, the global heap initialization. …
There’s a fallbackTSD, a thread local TSD for each thread:
TSD<Allocator> FallbackTSD; // <-----------
HybridMutex Mutex;
static thread_local ThreadState State;
static thread_local TSD<Allocator> ThreadTSD; // <-------------
The global shared TSDRegistrySharedT holds an array TSD<Allocator> TSDs[TSDsArraySize]; where each TSD has its allocator SizeClassAllocator and its QuarantineCache assigned to the current chosen allocator and Quarantine.
The exclusive one TSDRegistryExT holds object static thread_local TSD<Allocator> ThreadTSD;
Now, if scudo is build with flag SCUDO_ANDROID, we get the following parameters:
// scudo/standalone/allocator_config.h
struct AndroidConfig {
static const bool MaySupportMemoryTagging = true;
template <class A>
using TSDRegistryT = TSDRegistrySharedT<A, 8U, 2U>; // Shared, max 8 TSDs.
struct Primary {
using SizeClassMap = AndroidSizeClassMap;
#if SCUDO_CAN_USE_PRIMARY64
static const uptr RegionSizeLog = 28U;
typedef u32 CompactPtrT;
static const uptr CompactPtrScale = SCUDO_MIN_ALIGNMENT_LOG;
static const uptr GroupSizeLog = 20U;
static const bool EnableRandomOffset = true;
static const uptr MapSizeIncrement = 1UL << 18;
#else
static const uptr RegionSizeLog = 18U;
static const uptr GroupSizeLog = 18U;
typedef uptr CompactPtrT;
#endif
static const s32 MinReleaseToOsIntervalMs = 1000;
static const s32 MaxReleaseToOsIntervalMs = 1000;
};
#if SCUDO_CAN_USE_PRIMARY64
template <typename Config> using PrimaryT = SizeClassAllocator64<Config>;
#else
template <typename Config> using PrimaryT = SizeClassAllocator32<Config>;
#endif
struct Secondary {
struct Cache {
static const u32 EntriesArraySize = 256U;
static const u32 QuarantineSize = 32U;
static const u32 DefaultMaxEntriesCount = 32U;
static const uptr DefaultMaxEntrySize = 2UL << 20;
static const s32 MinReleaseToOsIntervalMs = 0;
static const s32 MaxReleaseToOsIntervalMs = 1000;
};
template <typename Config> using CacheT = MapAllocatorCache<Config>;
};
template <typename Config> using SecondaryT = MapAllocator<Config>;
};
So on Android systems, the shared TSD is used. Otherwise, in the default configuration, the exclusive one is used.
Continuing on the allocation path:
At a high level, Scudo has two backends. The primary allocator is the fast path for “normal” allocations that fit into pre-defined size classes. The secondary allocator is the fallback for requests that are too large, too awkwardly aligned, or otherwise do not fit cleanly in the primary class-based design. So before reading the code line by line, it helps to keep this split in mind: small and common requests try to stay in the primary, while large and exceptional ones end up in the secondary.
const Options Options = Primary.Options.load();
if (UNLIKELY(Alignment > MaxAlignment)) { // Check alignment
if (Options.get(OptionBit::MayReturnNull))
return nullptr;
reportAlignmentTooBig(Alignment, MaxAlignment);
}
if (Alignment < MinAlignment)
Alignment = MinAlignment;
It checks the alignment although the Alignment parameter is a hardcoded constant, so at least for malloc this won’t fail; But for some other cases, in case alignment is bigger than the maximum allowed, if the OptionBit::MayReturnNull is set to true, the allocation returns a NULL pointer.
A step further, if scudo is build with flag GWP_ASAN_HOOKS, it allocates guarded chunks, as the name suggest *ASAN which stands for AddressSanitizer.
#ifdef GWP_ASAN_HOOKS
if (UNLIKELY(GuardedAlloc.shouldSample())) {
if (void *Ptr = GuardedAlloc.allocate(Size, Alignment)) {
Stats.lock();
Stats.add(StatAllocated, GuardedAllocSlotSize);
Stats.sub(StatFree, GuardedAllocSlotSize);
Stats.unlock();
return Ptr;
}
}
#endif // GWP_ASAN_HOOKS
This part is not Scudo proper, but it is part of the real allocation path on builds that enable it, so it is still relevant. GWP-ASan is a sampling-based mitigation: instead of instrumenting every allocation like a traditional sanitizer build, it only diverts a small subset of allocations into specially guarded slots. That makes it cheap enough for production-like environments while still catching some heap bugs with strong signal when a sampled chunk gets hit.
Next up, it checks the filling options and the requested size alignment and limits:
const FillContentsMode FillContents = ZeroContents ? ZeroFill
: TSDRegistry.getDisableMemInit()
? NoFill
: Options.getFillContentsMode();
// If the requested size happens to be 0 (more common than you might think),
// allocate MinAlignment bytes on top of the header. Then add the extra
// bytes required to fulfill the alignment requirements: we allocate enough
// to be sure that there will be an address in the block that will satisfy
// the alignment.
const uptr NeededSize =
roundUp(Size, MinAlignment) +
((Alignment > MinAlignment) ? Alignment : Chunk::getHeaderSize());
// Takes care of extravagantly large sizes as well as integer overflows.
static_assert(MaxAllowedMallocSize < UINTPTR_MAX - MaxAlignment, "");
if (UNLIKELY(Size >= MaxAllowedMallocSize)) {
if (Options.get(OptionBit::MayReturnNull))
return nullptr;
// [...]
The NeededSize computation is worth slowing down for, because this is where the user-visible size stops being the allocator’s real internal size. Scudo rounds up the request, accounts for the hidden chunk header, and may reserve extra headroom so that the final returned pointer can satisfy alignment constraints without exposing allocator metadata to the caller.
Primary Allocator:
Now, we get to the actual allocation:
void *Block = nullptr;
uptr ClassId = 0;
uptr SecondaryBlockEnd = 0;
if (LIKELY(PrimaryT::canAllocate(NeededSize))) { // [5]
ClassId = SizeClassMap::getClassIdBySize(NeededSize);
DCHECK_NE(ClassId, 0U);
typename TSDRegistryT::ScopedTSD TSD(TSDRegistry); // [5.5]
Block = TSD->getSizeClassAllocator().allocate(ClassId);
// If the allocation failed, retry in each successively larger class until
// it fits. If it fails to fit in the largest class, fallback to the
// Secondary.
if (UNLIKELY(!Block)) { // [6]
while (ClassId < SizeClassMap::LargestClassId && !Block)
Block = TSD->getSizeClassAllocator().allocate(++ClassId);
if (!Block)
ClassId = 0;
}
}
if (UNLIKELY(ClassId == 0)) {
Block = Secondary.allocate(Options, Size, Alignment, &SecondaryBlockEnd,
FillContents);
}
At [5], the NeededSize requested by the user is checked against SizeClassMap::MaxSize:
On Android,
// scudo/standalone/size_class_map.h
static const uptr MaxSize = (1UL << Config::MaxSizeLog) + Config::SizeDelta;
// [...]
template <typename Config>
class FixedSizeClassMap : public SizeClassMapBase<Config> {
// [...]
struct AndroidSizeClassConfig {
#if SCUDO_WORDSIZE == 64U
static const uptr NumBits = 7;
static const uptr MinSizeLog = 4;
static const uptr MidSizeLog = 6;
static const uptr MaxSizeLog = 16;
static const u16 MaxNumCachedHint = 13;
static const uptr MaxBytesCachedLog = 13;
static constexpr uptr Classes[] = {
0x00020, 0x00030, 0x00040, 0x00050, 0x00060, 0x00070, 0x00090, 0x000b0,
0x000c0, 0x000e0, 0x00120, 0x00160, 0x001c0, 0x00250, 0x00320, 0x00450,
0x00670, 0x00830, 0x00a10, 0x00c30, 0x01010, 0x01210, 0x01bd0, 0x02210,
0x02d90, 0x03790, 0x04010, 0x04810, 0x05a10, 0x07310, 0x08210, 0x10010,
};
static const uptr SizeDelta = 16;
Again at [5] :
static bool canAllocate(uptr Size) { return Size <= SizeClassMap::MaxSize; }
So if NeededSize <= (1UL << Config::MaxSizeLog) + Config::SizeDelta;, i.e.
NeededSize <= 2**16 + 16 == 65552 bytes. OK…
So i case [5] is true, scudo uses the primary allocator to allocate the chunk from; next up, it grabs the ClassId ClassId = SizeClassMap::getClassIdBySize(NeededSize);
This is one of the core ideas of Scudo’s fast path: user requests are not managed as arbitrary byte lengths, but are first projected onto a discrete set of size classes. Once that mapping is done, the allocator only has to reason in terms of “give me one free block for class X”, which is much easier to cache and much faster to serve than a general-purpose variable-sized allocator path.
At [5.5], the primary allocator is initialized:
// scudo/standalone/combined.h
// The Cache must be provided zero-initialized.
void initAllocator(SizeClassAllocatorT *SizeClassAllocator) {
SizeClassAllocator->init(&Stats, &Primary);
}
and allocates from it:
// scudo/standalone/size_class_allocator.h
// For SizeClassAllocatorLocalCache: Allocates from Local Cache
void *allocate(uptr ClassId) {
DCHECK_LT(ClassId, NumClasses);
PerClass *C = &PerClassArray[ClassId];
if (C->Count == 0) {
// Refill half of the number of max cached.
DCHECK_GT(C->MaxCount / 2, 0U);
if (UNLIKELY(!refill(C, ClassId, C->MaxCount / 2)))
return nullptr;
DCHECK_GT(C->Count, 0);
}
// We read ClassSize first before accessing Chunks because it's adjacent to
// Count, while Chunks might be further off (depending on Count). That keeps
// the memory accesses in close quarters.
const uptr ClassSize = C->ClassSize;
CompactPtrT CompactP = C->Chunks[--C->Count];
Stats.add(StatAllocated, ClassSize);
Stats.sub(StatFree, ClassSize);
return Allocator->decompactPtr(ClassId, CompactP);
}
// For SizeClassAllocatorNoCache : Non Cached
void *allocate(uptr ClassId) {
CompactPtrT CompactPtr;
uptr NumBlocksPopped = Allocator->popBlocks(this, ClassId, &CompactPtr, 1U);
if (NumBlocksPopped == 0)
return nullptr;
DCHECK_EQ(NumBlocksPopped, 1U);
const PerClass *C = &PerClassArray[ClassId];
Stats.add(StatAllocated, C->ClassSize);
Stats.sub(StatFree, C->ClassSize);
return Allocator->decompactPtr(ClassId, CompactPtr);
}
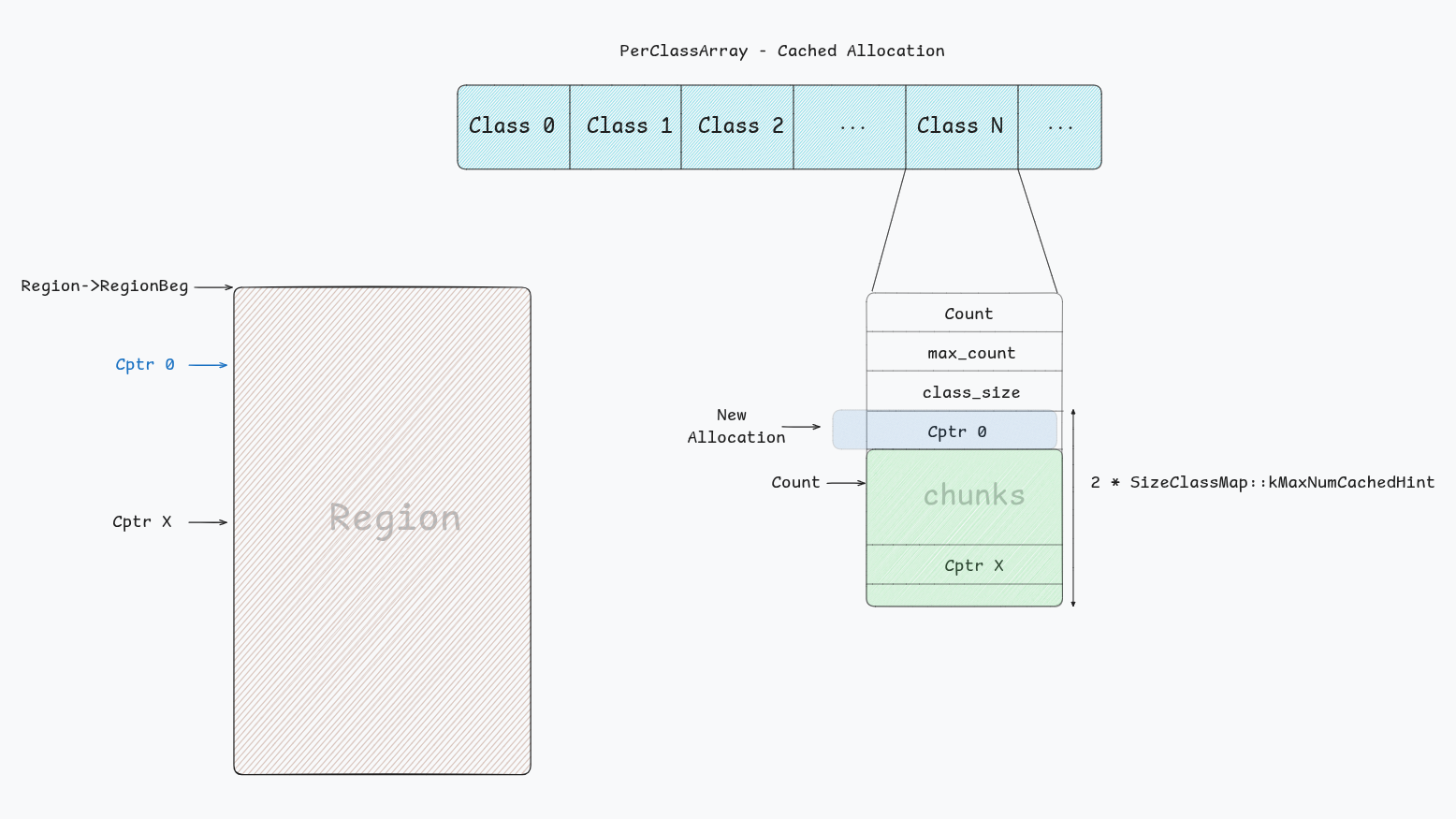
In case the allocation is cached, each class is represented by an instance this structure:
// sanitizer_common/sanitizer_allocator_local_cache.h
struct PerClass {
u32 count;
u32 max_count;
uptr class_size;
CompactPtrT chunks[2 * SizeClassMap::kMaxNumCachedHint];
};
Count: the number of available free chunks.max_count: maximum free chunks the class can hold.class_size: size of the chunks, e.g: 0x20, 0x50 or 0x1010 …etc.chunks: the array that holds the compressed addresses of the chunks.
Notice that here that allocations are selected like in a stack, with C->Count as a counter and an index at the same time that is decremented as a new allocation is made.
So this tiny per-class cache is effectively the hot front-end of the primary allocator..
But if the allocation fails, at [6] the allocation procedure loops over all the classes ( for Android 64bits ):
static constexpr uptr Classes[] = {
0x00020, 0x00030, 0x00040, 0x00050, 0x00060, 0x00070, 0x00090, 0x000b0,
0x000c0, 0x000e0, 0x00120, 0x00160, 0x001c0, 0x00250, 0x00320, 0x00450,
0x00670, 0x00830, 0x00a10, 0x00c30, 0x01010, 0x01210, 0x01bd0, 0x02210,
0x02d90, 0x03790, 0x04010, 0x04810, 0x05a10, 0x07310, 0x08210, 0x10010,
};
Until the allocation succeeds, or classes ran out; in the latter case, the secondary allocator will be used;
if (UNLIKELY(ClassId == 0)) {
Block = Secondary.allocate(Options, Size, Alignment, &SecondaryBlockEnd,
FillContents);
Last step,
const uptr UserPtr = roundUp(
reinterpret_cast<uptr>(Block) + Chunk::getHeaderSize(), Alignment);
const uptr SizeOrUnusedBytes =
ClassId ? Size : SecondaryBlockEnd - (UserPtr + Size);
if (LIKELY(!useMemoryTagging<AllocatorConfig>(Options))) {
return initChunk(ClassId, Origin, Block, UserPtr, SizeOrUnusedBytes,
FillContents); // <------
}
return initChunkWithMemoryTagging(ClassId, Origin, Block, UserPtr, Size,
SizeOrUnusedBytes, FillContents);
The pointer UserPtr to get returned is incremented by the header’s size(so that the user doesn’t overwrite them obviously), and then there’s MTE tagging part that i’ll get to later.
At last, the chunk is initialized using :
if (LIKELY(!useMemoryTagging<AllocatorConfig>(Options))) {
return initChunk(ClassId, Origin, Block, UserPtr, SizeOrUnusedBytes,
FillContents);
}
// [...]
Header.ClassId = ClassId & Chunk::ClassIdMask;
Header.State = Chunk::State::Allocated;
Header.setOrigin(Origin);
Header.SizeOrUnusedBytes = SizeOrUnusedBytes & Chunk::SizeOrUnusedBytesMask;
Chunk::storeHeader(Cookie, reinterpret_cast<void *>(addHeaderTag(UserPtr)),
&Header);
return reinterpret_cast<void *>(UserPtr);
By the time initChunk(...) returns, Scudo has converted a raw backend block into something with allocator-owned metadata and an explicit state transition. The stored header ties that user pointer back to its size class, origin, and size information, which is what later lets free validate and route the chunk correctly.
Secondary Allocator:
The secondary allocator is the “not worth squeezing into a size class” backend. In practice, it handles requests that exceed the primary cutoff and often ends up relying more directly on page-level mappings. This is slower than the primary fast path, but it avoids forcing huge or unusual allocations into data structures that were optimized for small fixed-size blocks.
Regions:
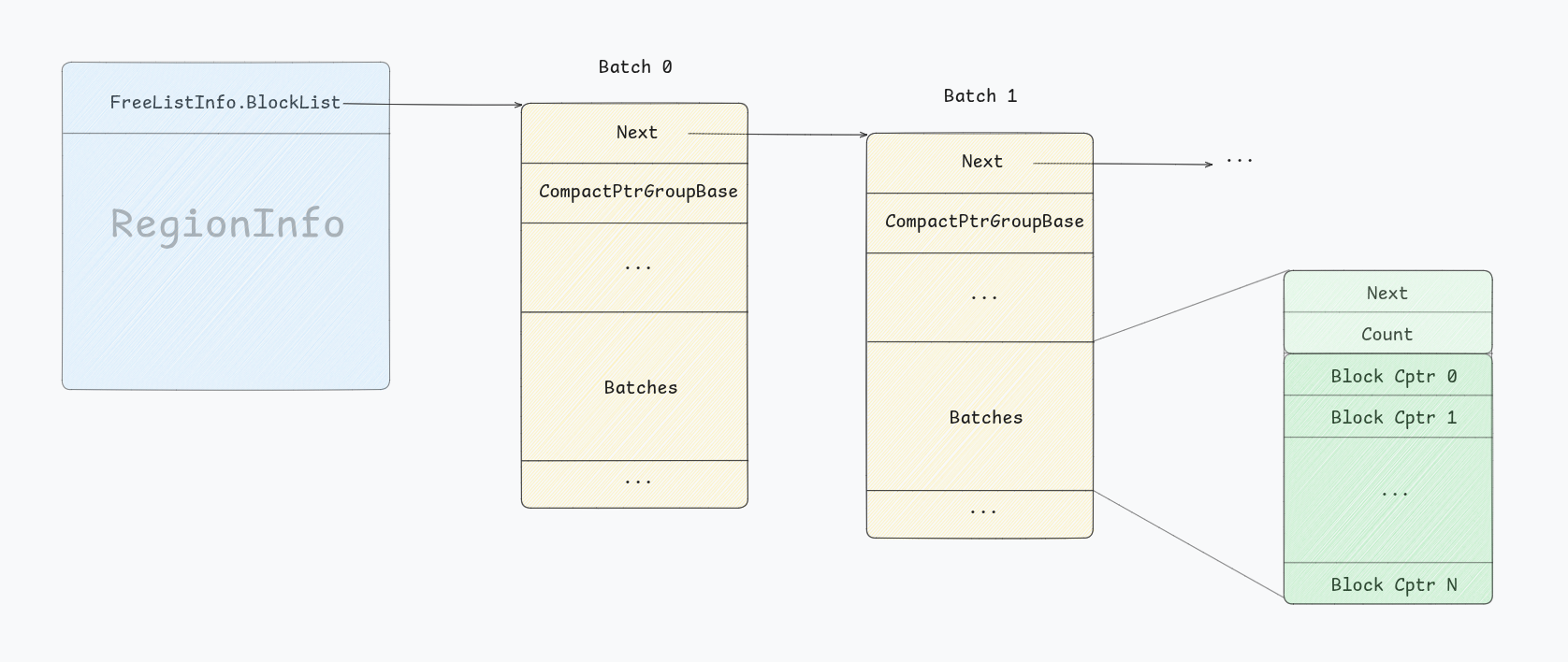
Each ClassId has backing memory called a region; It is presented by an object RegionInfo that holds a pointer to groups of batches where this class refills it chunks from; each region is of size 2^RegionSizeLog. For each class its correspondent Region is stored in array RegionInfoArray and has a getter:
// scudo/standalone/primary64.h
RegionInfo *getRegionInfo(uptr ClassId) {
DCHECK_LT(ClassId, NumClasses);
return &RegionInfoArray[ClassId]; // <-----
}
// From the sources comments
// SizeClassAllocator64 is an allocator tuned for 64-bit address space.
// It starts by reserving NumClasses * 2^RegionSizeLog bytes, equally divided in
// Regions, specific to each size class. Note that the base of that mapping is
// random (based to the platform specific map() capabilities). If
// PrimaryEnableRandomOffset is set, each Region actually starts at a random
// offset from its base.
//
// Regions are mapped incrementally on demand to fulfill allocation requests,
// those mappings being split into equally sized Blocks based on the size class
// they belong to. The Blocks created are shuffled to prevent predictable
// address patterns (the predictability increases with the size of the Blocks).
//
// The 1st Region (for size class 0) holds the Batches. This is a
// structure used to transfer arrays of available pointers from the class size
// freelist to the thread specific freelist, and back.
//
// The memory used by this allocator is never unmapped, but can be partially
// released if the platform allows for it.
The easiest mental model for a region is: “the long-lived backing area for one size class”. Instead of mixing all block sizes together, Scudo reserves a dedicated region for each class and carves it into equal-sized blocks on demand. That keeps metadata localized, simplifies accounting, and makes allocation/free behavior more regular than in classic allocators that freely interleave differently sized chunks in the same arenas.
// scudo/standalone/primary64.h
struct UnpaddedRegionInfo {
// Mutex for operations on freelist
HybridMutex FLLock;
ConditionVariableT FLLockCV GUARDED_BY(FLLock);
// Mutex for memmap operations
HybridMutex MMLock ACQUIRED_BEFORE(FLLock);
// `RegionBeg` is initialized before thread creation and won't be changed.
uptr RegionBeg = 0;
u32 RandState GUARDED_BY(MMLock) = 0;
BlocksInfo FreeListInfo GUARDED_BY(FLLock);
PagesInfo MemMapInfo GUARDED_BY(MMLock);
ReleaseToOsInfo ReleaseInfo GUARDED_BY(MMLock) = {};
bool Exhausted GUARDED_BY(MMLock) = false;
bool isPopulatingFreeList GUARDED_BY(FLLock) = false;
};
struct RegionInfo : UnpaddedRegionInfo {
char Padding[SCUDO_CACHE_LINE_SIZE -
(sizeof(UnpaddedRegionInfo) % SCUDO_CACHE_LINE_SIZE)] = {};
};
Each region has a BlocksInfo FreeListInfo member that holds information about the free blocks in the region, and tracks PushedBlocks/ PoppedBlocks:
struct BlocksInfo {
SinglyLinkedList<BatchGroupT> BlockList = {};
uptr PoppedBlocks = 0;
uptr PushedBlocks = 0;
};
uptr RegionBeg that holds a randomized beginning address to increase security EnableRandomOffset is set true.
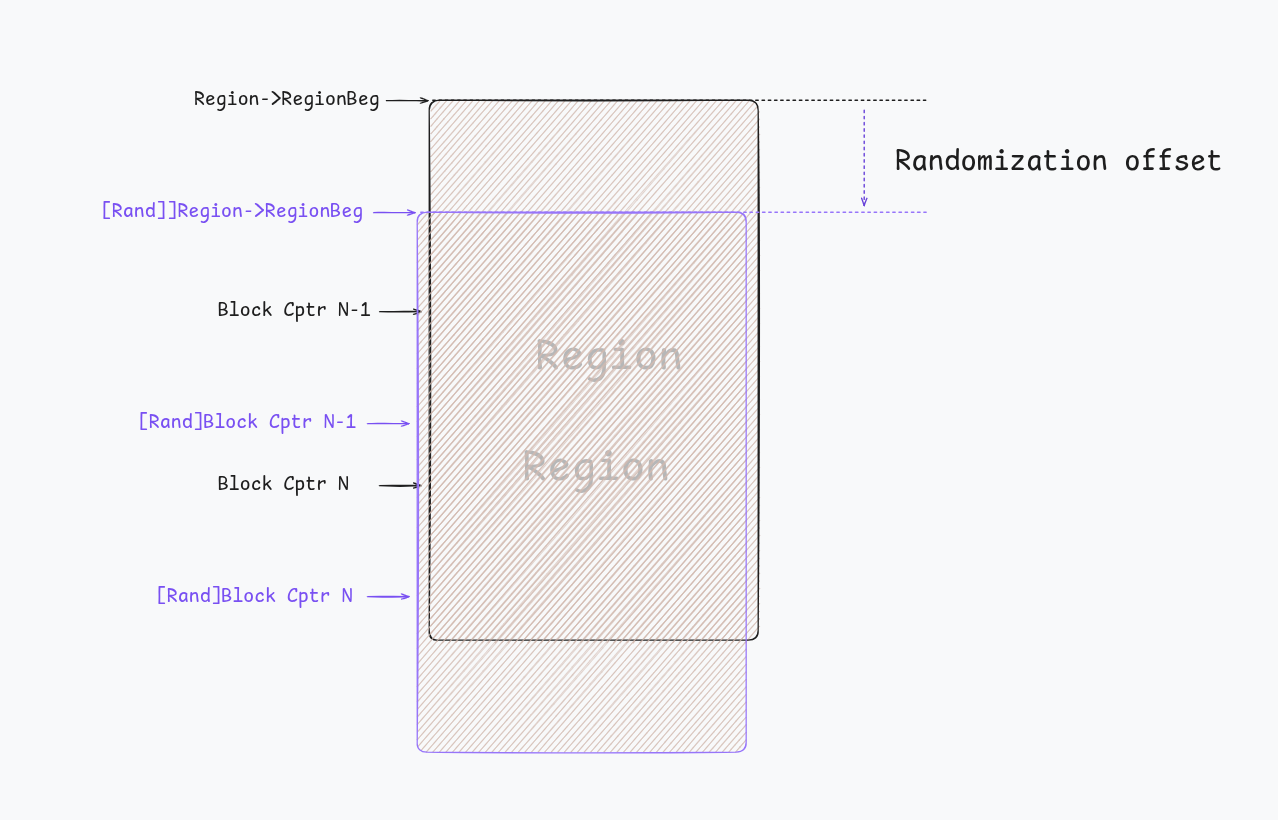
MemMapInfo holds the information about the region mapping in the process.
That random offset matters because even though a region is conceptually “the area for class X”, Scudo does not want the actual block layout to become too predictable across runs. Small layout perturbations are not a silver bullet, but they do raise the cost of exploits.
Here’s the initialization procedure:
// scudo/standalone/primary64.h
template <typename Config>
void SizeClassAllocator64<Config>::initRegion(RegionInfo *Region, uptr ClassId,
MemMapT MemMap,
bool EnableRandomOffset)
REQUIRES(Region->MMLock) {
DCHECK(!Region->MemMapInfo.MemMap.isAllocated());
DCHECK(MemMap.isAllocated());
const uptr PageSize = getPageSizeCached();
Region->MemMapInfo.MemMap = MemMap;
Region->RegionBeg = MemMap.getBase();
if (EnableRandomOffset) {
Region->RegionBeg += (getRandomModN(&Region->RandState, 16) + 1) * PageSize;
}
const uptr BlockSize = getSizeByClassId(ClassId);
// Releasing small blocks is expensive, set a higher threshold to avoid
// frequent page releases.
if (isSmallBlock(BlockSize)) {
Region->ReleaseInfo.TryReleaseThreshold =
PageSize * SmallerBlockReleasePageDelta;
} else {
Region->ReleaseInfo.TryReleaseThreshold =
getMinReleaseAttemptSize(BlockSize);
}
}
Refilling Chunks:
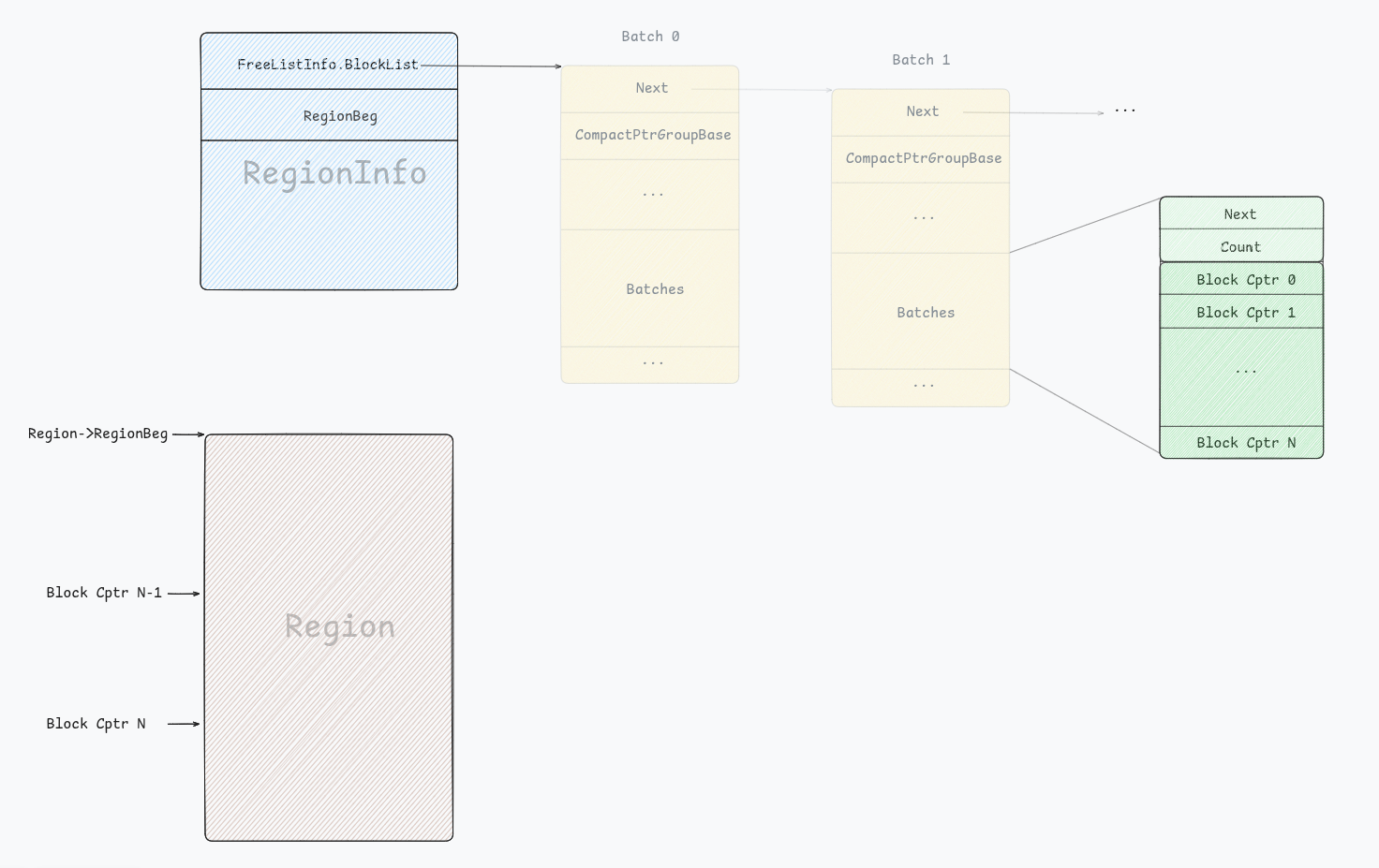
When there’s no more chunks to allocate, i.e the class’s chunks count is null:
void *allocate(uptr ClassId) {
// [...]
PerClass *C = &PerClassArray[ClassId];
if (C->Count == 0) { // <--------
// [...]
}
The allocator needs to refill the chunks. And to do so, at the very bottom it calls this function:
// scudo/standalone/primary64.h
template <typename Config>
u16 SizeClassAllocator64<Config>::popBlocksImpl(
SizeClassAllocatorT *SizeClassAllocator, uptr ClassId, RegionInfo *Region,
CompactPtrT *ToArray, const u16 MaxBlockCount) REQUIRES(Region->FLLock)
{
SizeClassAllocatoris the that requested the refill, either one of Primary or Secondary.ClassIdis the class size that needs to be refillled.regionis the corresponding object that holds freelists that backsClassId.ToArrayisC->Chunksdirectly.MaxBlockCountis used as a bound for chunks refelling.
Step I: It checks that the region’s freelist has available at least one BatchGroup, and grabs the first one, the head of the list:
if (Region->FreeListInfo.BlockList.empty())
return 0U;
SinglyLinkedList<BatchT> &Batches =
Region->FreeListInfo.BlockList.front()->Batches;
Step II: Get the first batch, from of the list, and copy the addresses(Compressed pointers) inside into to array:
// [...]
BatchT *B = Batches.front();
DCHECK_NE(B, nullptr);
DCHECK_GT(B->getCount(), 0U);
// BachClassId should always take all blocks in the Batch. Read the
// comment in `pushBatchClassBlocks()` for more details.
const u16 PopCount = ClassId == SizeClassMap::BatchClassId
? B->getCount()
: Min(MaxBlockCount, B->getCount());
B->moveNToArray(ToArray, PopCount);
Populating the freelist:
When the freelist blocks them selves are empty,
// scudo/standalone/primary64.h
template <typename Config>
u16 SizeClassAllocator64<Config>::populateFreeListAndPopBlocks(
SizeClassAllocatorT *SizeClassAllocator, uptr ClassId, RegionInfo *Region,
CompactPtrT *ToArray, const u16 MaxBlockCount) REQUIRES(Region->MMLock)
EXCLUDES(Region->FLLock) {
if (!Config::getEnableContiguousRegions() &&
!Region->MemMapInfo.MemMap.isAllocated()) {
ReservedMemoryT ReservedMemory;
if (UNLIKELY(!ReservedMemory.create(/*Addr=*/0U, RegionSize,
"scudo:primary_reserve",
MAP_ALLOWNOMEM))) { // [8]
Printf("Can't reserve pages for size class %zu.\n",
getSizeByClassId(ClassId));
return 0U;
}
initRegion(Region, ClassId,
ReservedMemory.dispatch(ReservedMemory.getBase(),
ReservedMemory.getCapacity()),
/*EnableRandomOffset=*/false); // [9]
}
The actual hard allocation is done from [8] using down the line:
// scudo/standalone/mem_map.cpp
bool MemMapDefault::mapImpl(uptr Addr, uptr Size, const char *Name,
uptr Flags) {
void *MappedAddr =
::scudo::map(reinterpret_cast<void *>(Addr), Size, Name, Flags, &Data);
if (MappedAddr == nullptr)
return false;
Base = reinterpret_cast<uptr>(MappedAddr);
MappedBase = Base;
Capacity = Size;
return true;
}
// scudo/standalone/common.h
// Our platform memory mapping use is restricted to 3 scenarios:
// - reserve memory at a random address (MAP_NOACCESS);
// - commit memory in a previously reserved space;
// - commit memory at a random address.
// As such, only a subset of parameters combinations is valid, which is checked
// by the function implementation. The Data parameter allows to pass opaque
// platform specific data to the function.
// Returns nullptr on error or dies if MAP_ALLOWNOMEM is not specified.
void *map(void *Addr, uptr Size, const char *Name, uptr Flags = 0,
MapPlatformData *Data = nullptr);
// scudo/standalone/linux.cpp
void *map(void *Addr, uptr Size, UNUSED const char *Name, uptr Flags,
UNUSED MapPlatformData *Data) {
int MmapFlags = MAP_PRIVATE | MAP_ANONYMOUS;
int MmapProt;
if (Flags & MAP_NOACCESS) {
MmapFlags |= MAP_NORESERVE;
MmapProt = PROT_NONE;
} else {
MmapProt = PROT_READ | PROT_WRITE;
}
#if defined(__aarch64__)
#ifndef PROT_MTE
#define PROT_MTE 0x20
#endif
if (Flags & MAP_MEMTAG)
MmapProt |= PROT_MTE;
#endif
if (Addr)
MmapFlags |= MAP_FIXED;
void *P = mmap(Addr, Size, MmapProt, MmapFlags, -1, 0);
if (P == MAP_FAILED) {
if (!(Flags & MAP_ALLOWNOMEM) || errno != ENOMEM)
reportMapError(errno == ENOMEM ? Size : 0);
return nullptr;
}
#if SCUDO_ANDROID
if (Name)
prctl(ANDROID_PR_SET_VMA, ANDROID_PR_SET_VMA_ANON_NAME, P, Size, Name);
#endif
return P;
}
Once the mapping is done, at [9] the freelist is refilled by reinitializing the region.
What is nice about this split is that Scudo separates reservation, mapping, and serving blocks fairly cleanly. A region can exist conceptually before all of its pages are committed, and actual block production only happens when demand reaches that class. So even though the allocator reserves large virtual ranges, physical backing and usable chunks still appear lazily.
DELETING PATH - FREE
The free path mirrors the allocation path in structure, but its first priority is validation rather than speed. Before Scudo gives a block back to any cache or region, it reloads the hidden header, checks that the checksum still matches, and verifies that the chunk is currently in the Allocated state. Only after those checks pass does it decide whether the chunk should be quarantined or returned directly to the allocator backend.
Normal Deallocation - Cached
// scudo/standalone/combined.cpp
ALWAYS_INLINE void deallocate(void *Ptr, Chunk::Origin Origin) {
deallocate(Ptr, Origin, /*DeleteSize=*/0, /*DeleteAlignment=*/0);
}
// [...]
NOINLINE void deallocate(void *Ptr, u8 DeallocOrigin, uptr DeleteSize,
uptr DeleteAlignment) {
if (UNLIKELY(!Ptr))
return;
// [...]
Chunk::UnpackedHeader Header;
Chunk::loadHeader(Cookie, Ptr, &Header); // <----
if (UNLIKELY(Header.State != Chunk::State::Allocated)) // <----
reportInvalidChunkState(AllocatorAction::Deallocating, Ptr);
// [...]
quarantineOrDeallocateChunk(Options, TaggedPtr, &Header, Size);
}
- Use-After-Free and chunk corruption verification using:
inline void loadHeader(u32 Cookie, const void *Ptr,
UnpackedHeader *NewUnpackedHeader) {
PackedHeader NewPackedHeader = atomic_load_relaxed(getConstAtomicHeader(Ptr));
*NewUnpackedHeader = bit_cast<UnpackedHeader>(NewPackedHeader);
if (UNLIKELY(NewUnpackedHeader->Checksum !=
computeHeaderChecksum(Cookie, Ptr, NewUnpackedHeader)))
reportHeaderCorruption(NewUnpackedHeader, Ptr);
}
Apriori, UAF is still possible, but the attacker will have to forge the checksum.
- Double free verification by checking the chunk’s state:
Header.State != Chunk::State::Allocated
TODO: More about the Cookie and checksum
The important thing about the cookie is that the header checksum is not just a checksum of the header bytes in isolation. It is derived using the process-specific cookie and the pointer value, which means the attacker does not get a reusable “write these bytes and the header becomes valid everywhere” primitive. In practice that does not make corruption impossible, but it does mean many classic heap tricks now need either an information leak or a way to preserve header integrity while corrupting adjacent state.
Easy visual to understand.
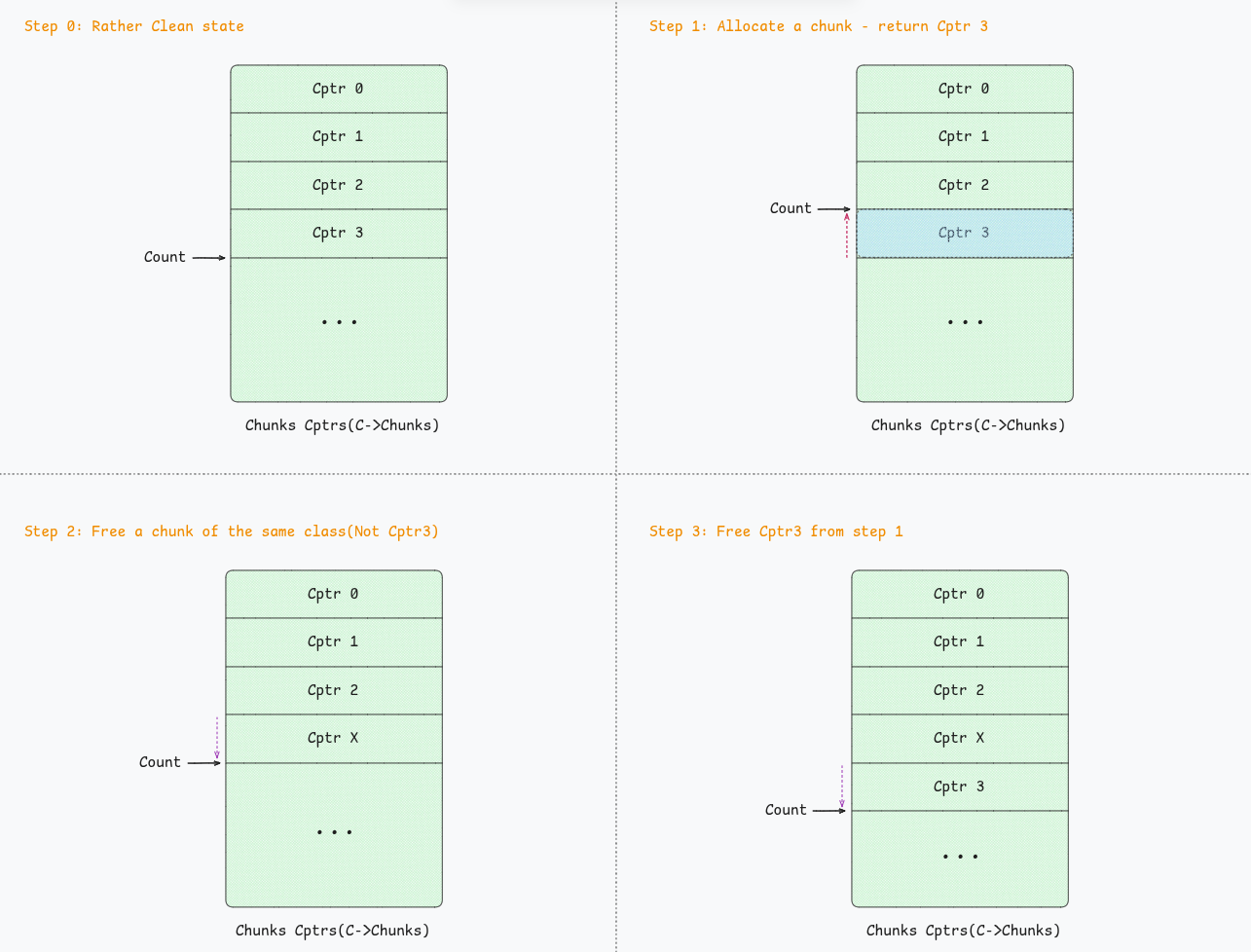
If, C->Count >= C->MaxCount, meaning the chunks array is full, half of the array is drained so that freeing becomes possible:
// scudo/standalone/size_class_allocator.h
bool deallocate(uptr ClassId, void *P) {
CHECK_LT(ClassId, NumClasses);
PerClass *C = &PerClassArray[ClassId];
// If the cache is full, drain half of blocks back to the main allocator.
const bool NeedToDrainCache = C->Count == C->MaxCount;
if (NeedToDrainCache)
drain(C, ClassId); // <-------
// See comment in allocate() about memory accesses.
const uptr ClassSize = C->ClassSize;
C->Chunks[C->Count++] =
Allocator->compactPtr(ClassId, reinterpret_cast<uptr>(P));
Stats.sub(StatAllocated, ClassSize);
Stats.add(StatFree, ClassSize);
return NeedToDrainCache;
}
This is the symmetric operation to the allocation fast path we saw earlier. While malloc pops compact pointers from a per-class cache until it goes empty, free pushes compact pointers back until that cache goes full. Once it is full, half of it is flushed to the backend so the local cache stays bounded instead of growing without limit.
Quarantine
// scudo/standalone/combined.h
void quarantineOrDeallocateChunk(const Options &Options, void *TaggedPtr,
Chunk::UnpackedHeader *Header,
uptr Size) NO_THREAD_SAFETY_ANALYSIS {
void *Ptr = getHeaderTaggedPointer(TaggedPtr);
// If the quarantine is disabled, the actual size of a chunk is 0 or larger
// than the maximum allowed, we return a chunk directly to the backend.
// This purposefully underflows for Size == 0.
const bool BypassQuarantine = AllocatorConfig::getQuarantineDisabled() ||
!Quarantine.getCacheSize() ||
((Size - 1) >= QuarantineMaxChunkSize) ||
!Header->ClassId;
if (BypassQuarantine)
Header->State = Chunk::State::Available;
else
Header->State = Chunk::State::Quarantined;
// [...]
if (UNLIKELY(useMemoryTagging<AllocatorConfig>(Options)))
retagBlock(Options, TaggedPtr, Ptr, Header, Size, false);
typename TSDRegistryT::ScopedTSD TSD(TSDRegistry);
Quarantine.put(&TSD->getQuarantineCache(),
QuarantineCallback(*this, TSD->getSizeClassAllocator()),
Ptr, Size); // <------
First off, the Quarantine is not always used for every deallocation, and here are what “bypasses” it:
- If it is disabled by default.
- Or its cache size is 0
- Or the freed chunk has size > QuarantineMaxChunkSize, that the quarantine does not support.
- Or the freed chunk belongs to classId 0.
If none of these are true, the chunk is put into Quarantine Chunk::State::Quarantined.
Now, what does Quarantine-ing means ?
Conceptually, quarantine is just delayed reuse. Instead of making a freshly freed chunk immediately available for the next allocation of the same class, Scudo keeps it in an intermediate holding area for a while. That delay is extremely valuable defensively, because many heap exploits depend on reusing a freed object quickly and predictably before the program has a chance to notice the stale reference.
The quarantine hold list of QuarantineBatches, each Batch
// scudo/standalone/quarantine.h
void put(CacheT *C, Callback Cb, Node *Ptr, uptr Size) {
C->enqueue(Cb, Ptr, Size);
if (C->getSize() > getCacheSize())
drain(C, Cb); // [12]
}
// [...]
void enqueue(Callback Cb, void *Ptr, uptr Size) {
if (List.empty() || List.back()->Count == QuarantineBatch::MaxCount) {
QuarantineBatch *B =
reinterpret_cast<QuarantineBatch *>(Cb.allocate(sizeof(*B)));
DCHECK(B);
B->init(Ptr, Size);
enqueueBatch(B);
} else {
List.back()->push_back(Ptr, Size);
addToSize(Size);
}
}
// [...]
void push_back(void *Ptr, uptr Size) {
DCHECK_LT(Count, MaxCount);
Batch[Count++] = Ptr;
this->Size += Size;
}
// [...]
C->enqueue(Cb, Ptr, Size); basically as we said, a QuarantineCache instance contains a list of batches and each batch has an array of MaxCount == 1019 , that is, each batch can store up to 1019 pointers, that are quarantined pointers.
How are these pointers reclaimed ?
- When a pointer is put into quarantine, at [12], if
getCacheSize()(which is the maximum size of the per-thread Quarantine cache(configuration with paramthread_local__quarantine_size_kb)), is inferior the current sizeC->getSize()i.e: the number of pointers in the Quarantine.
The pointers are simply deallocated with
void recycle(void *Ptr) {
Chunk::UnpackedHeader Header;
Chunk::loadHeader(Allocator.Cookie, Ptr, &Header);
if (UNLIKELY(Header.State != Chunk::State::Quarantined))
reportInvalidChunkState(AllocatorAction::Recycling, Ptr);
Header.State = Chunk::State::Available;
Chunk::storeHeader(Allocator.Cookie, Ptr, &Header);
if (allocatorSupportsMemoryTagging<AllocatorConfig>())
Ptr = untagPointer(Ptr);
void *BlockBegin = Allocator::getBlockBegin(Ptr, &Header);
SizeClassAllocator.deallocate(Header.ClassId, BlockBegin);
}
After some merging work, the recycling function takes all Quarantine Batches and for each batch, it deallocates pointers Batch[i] , that is, all the pointers stored in the batch array.
So quarantine is not a separate forever-heap; it is just a staging layer in front of the normal backend free path. Chunks eventually come back to the allocator, but only after spending some time in a structure that intentionally breaks the “free now, reuse immediately” behavior many bugs depend on.
- The second case is when
mallopt(...)is called which forces Quarantine draining, by triggers the following sequence:
// scudo/standalone/combined.h
// [...]
void drainCaches() { TSDRegistry.drainCaches(this); } // 1
// scudo/standalone/tsd_shared.h
void drainCaches(Allocator *Instance) { // 2
ScopedLock L(Mutex);
for (uptr I = 0; I < NumberOfTSDs; ++I) {
TSDs[I].lock();
Instance->drainCache(&TSDs[I]);
TSDs[I].unlock();
}
void drainCache(TSD<ThisT> *TSD) { // 3
TSD->assertLocked(/*BypassCheck=*/true);
if (!AllocatorConfig::getQuarantineDisabled()) {
Quarantine.drainAndRecycle( // <-------
&TSD->getQuarantineCache(),
QuarantineCallback(*this, TSD->getSizeClassAllocator()));
}
TSD->getSizeClassAllocator().drain();
}
}
There are really two levels here. The thread-local QuarantineCache is the fast ingestion point where a thread first drops freed chunks, while the global quarantine logic decides when caches must be drained and recycled to keep overall memory usage under control. So, just like the primary allocator itself, Scudo again combines a cheap local fast path with a more coordinated global mechanism in the background.
What’s Left To do:
This post is meant to be an introduction to more posts to come in the future; there’s many components to analyze: MTE, Guarded ASAN Allocator & of course, thinking about mitigation bypasses, even though let me tell you, this seems to be no easy task.
Each file’s functionality
If you are navigating the source for the first time, the easiest way is to treat it as a pipeline: wrappers at the front, combined.h as the main dispatcher, TSD files for per-thread state, primary/secondary backends for actual block sourcing, and quarantine code for delayed frees.
wrappers_c.cpp : handles heap operations in C (malloc, free, realloc…etc)
wrappers_cpp.cpp : handles heap operations in C++ (new, delete …etc)
combined.h : implements the core logic
tsd_shared.h / tsd_exclusive.h : describe how allocator state is attached to threads.
primary64.h : implements the 64-bit size-class primary backend and its regions / batches logic.
secondary.h and related mapping code : handle large allocations that bypass the primary size classes.
quarantine.h : implements delayed reuse of freed chunks through quarantine batches and recycling.
References:
- https://source.android.com/docs/security/test/scudo?hl=fr
- https://www.l3harris.com/newsroom/editorial/2023/10/scudo-hardened-allocator-unofficial-internals-documentation
- https://un1fuzz.github.io/articles/scudo_internals.html
- https://nebelwelt.net/files/24WOOT.pdf
- https://llvm.org/docs/ScudoHardenedAllocator.html
- Video: https://www.youtube.com/watch?v=Gnyc0VP2-JU